
这是一个创建于 464 天前的主题,其中的信息可能已经有所发展或是发生改变。
最近想做个中文的问答系统, 大致的流程如下:
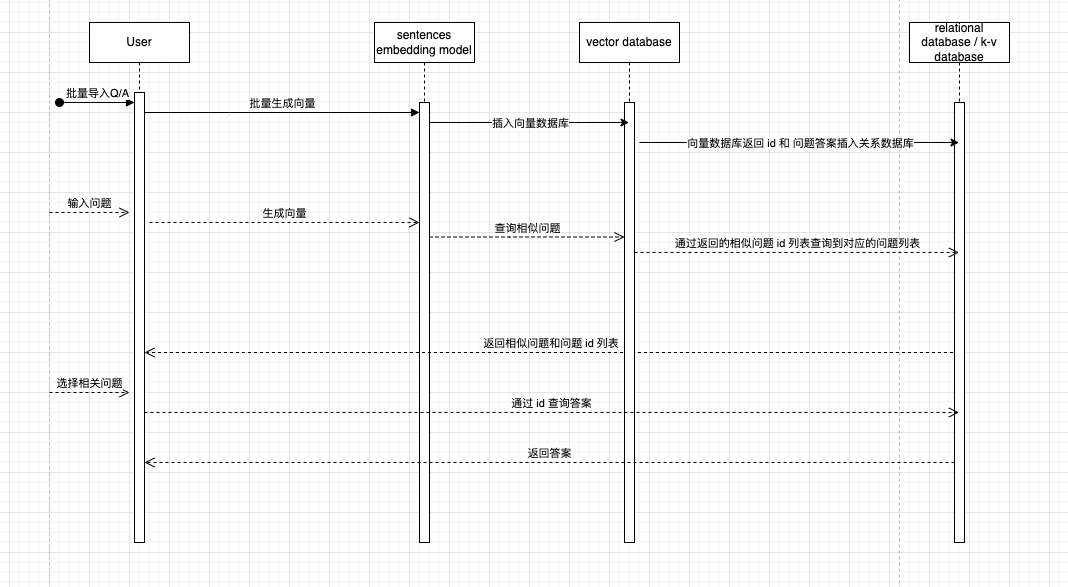
问题和对应的答案是固定的,通过 sentence embedding model 把问题转化为向量存储在向量数据库,把用户输入的问题转化为向量并在向量数据库中查询的最匹配的 k 个问题,然后用户选择问题,并返回具体答案。
涉及到 embedding 模型的选择问题, 主要想找一个中文匹配度好的,我在 hugging face 看了模型的排名
https://huggingface.co/spaces/mteb/leaderboard
请教一下我这种场景应该关注模型的什么参数,有不错的模型也可以推荐一下,先谢谢啦。
第 1 条附言 · 2023-08-08 10:01:53 +08:00
最后我们选择使用 openai 的 embedding 接口。
 |
1
flyingfz 2023-07-25 15:28:22 +08:00
|
|
2
flyingfz 2023-07-25 15:30:59 +08:00
测试过几个,最后凭感觉选用了
https://huggingface.co/shibing624/text2vec-base-chinese-paraphrase 也在继续探索 。 mteb/leaderboard 的这些指标不懂啊 😂 |
|
3
flyingfz 2023-07-25 16:01:37 +08:00
|
 |
4
codingbody OP @flyingfz #2 谢谢,我也在探索探索😂
|
|
5
codingbody OP @flyingfz #3 这是要自己训练 embedding 模型么
|
 |
6
seanlee97 2023-10-30 11:47:52 +08:00
|