
ACG2Vec 系列之 RecSys4Pix——如何构建最小化现代推荐系统实例
OysterQAQ · OysterQAQ · 2024 年 2 月 20 日 · 6317 次点击这是一个创建于 726 天前的主题,其中的信息可能已经有所发展或是发生改变。
前言
经过一年多将近两年的学习,我将推荐系统作为研究生期间的主要研究方向。在这个过程中,我深入阅读了许多论文和资料,对我的研究起到了很大的帮助。以下是一些主要的非论文资料:
在网络上接受了一些几乎无偿的知识分享,积累了一些个人心得体会,并进行了一些粗浅的实践。以下是我在实践中得到的经验分享,希望对推荐系统的新手有所帮助,在学习理论知识的同时,能够更好地理解现代推荐系统的构成与工作流程。请注意,这些实践仅基于个人学习经验,如有错误,望谅解。
本文适合有一定推荐算法基础的同学阅读,md 文件和 xmind 文件位于 https://github.com/OysterQAQ/ACG2vec 的 model 文件夹
概览
推荐系统作为搜广推的一部分,在互联网信息爆炸导致信息过载的背景下,经历了机器学习时代后,现代推荐系统主要以深度学习技术为基础进行了一系列的发展。以下是本次实例的整体架构图:
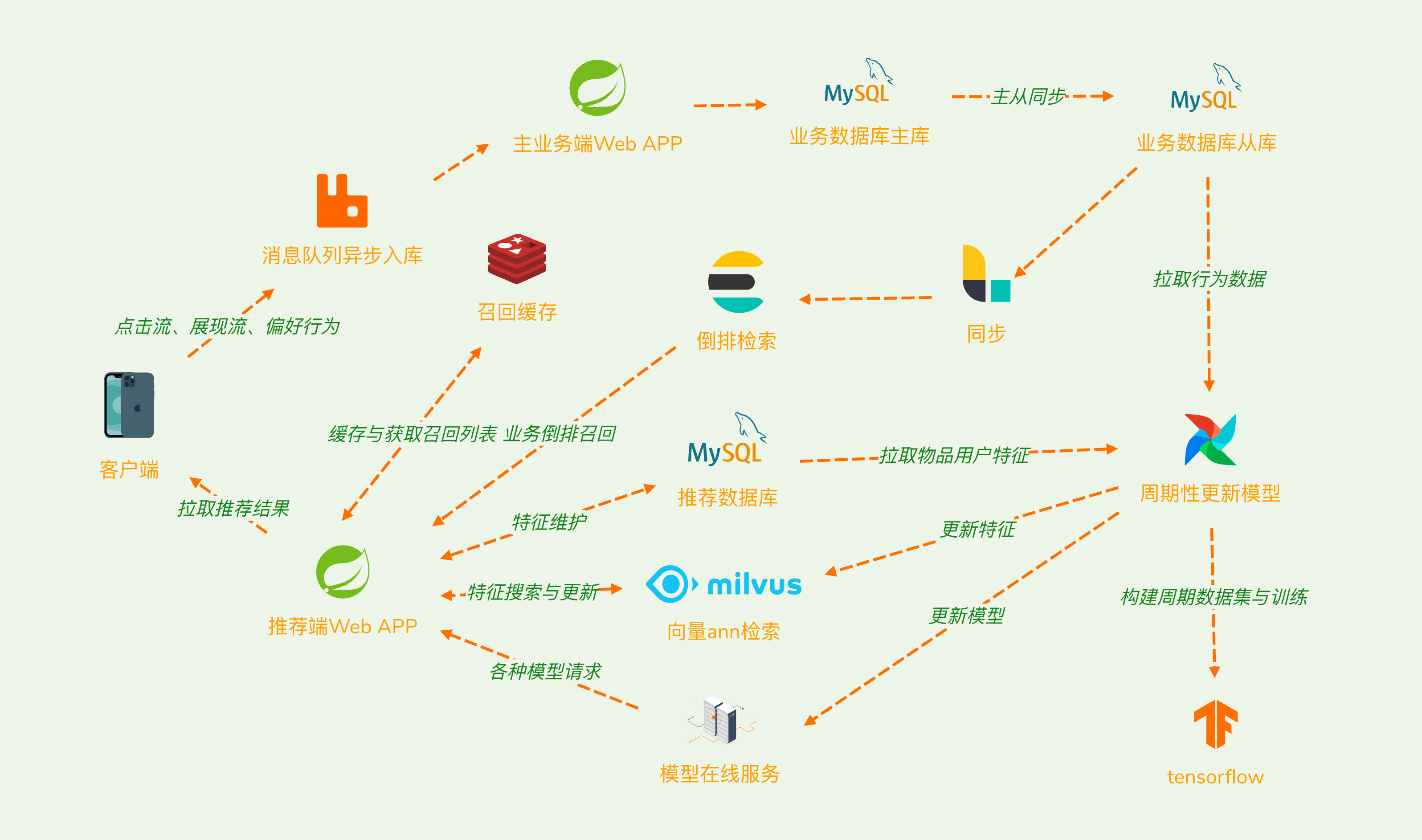
为了提高推荐系统的性能、可扩展性和效率与更灵活的数据同步和处理,我们分离业务端与推荐模块,采用了 MySQL 主从同步功能,将业务库同步到推荐专用的只读业务从库。在企业实践中,应该配合大数据处理构建更完善的数据仓库,以满足算法需求。同时,使用 Airflow 作为调度系统,自动化完成周期性任务,包括构建数据集、训练、部署新模型、更新特征向量等工作。
推荐模型所依托的深度学习技术栈主要以 TensorFlow 为主导,包括了 TF-Serving 来提供模型的在线推断。为了满足了不同类型的召回需求,引入了 Elasticsearch 来完成倒排检索相关的功能,同时使用 Milvus 作为向量检索引擎,完成向量召回的任务。
下文主要分为 5 个章节来描述
- 数据示例:将详细描述未处理的输入数据,以使读者能够深入了解整个推荐系统的场景上下文。通过展示原始数据,我们将引导读者了解推荐系统工作的基础,并为后续章节建立起清晰的背景。
- 深度学习时代的特征工程:介绍在深度学习时代中的特征工程。我们将描述如何对输入数据进行处理,以及如何运用内容抽取算法来提取特征。细致探讨特征工程的实现,包括一些特征维护的关键细节,以确保模型训练得到高质量的特征。
- 召回:召回作为推荐系统的重要组成部分,这一章节将详细解释在当前场景下使用的多路召回策略。我们将讨论不同召回方法的选择,以及一些工程细节,确保召回环节能够高效、准确地提供候选集。
- 排序:和在投论文高度重复,仅作占位。( arxiv 链接: https://arxiv.org/abs/2402.10381 )
- 重排:对于 DDP 算法进行描述
- A/B 测试与指标监控:暂无内容,仅作占位
数据示例
在本场景中,推荐系统涉及两大类实体:Item (画作)和 User (用户),最终目标是为每个用户找到其感兴趣的画作列表,并对其进行排序。以下表格展示了画作与用户未经过特征工程的最原始输入( raw input ):
Item
| 特征 | 类型 | 描述 | 示例 |
|---|---|---|---|
| illust_id | int | 画作 id | 115907684 |
| artist_id | int | 画师 id | 90834793 |
| tags | List<String> | 标签 json | [{"name":"キサキ(ブルーアーカイブ)","translatedName":"妃咲(蔚蓝档案)","id":2996811958},{"name":"ブルーアーカイブ","translatedName":"碧蓝档案","id":602421493},{"name":"ブルアカ","translatedName":"","id":306311799}] |
| width | int | 首图宽度 | 2362 |
| height | int | 首图高度 | 4724 |
| sanity_level | int | 年龄分级 | 2 |
| restrict | int | 是否限制级 | 0 |
| x_restrict | int | 更加严格的限制级 | 0 |
| total_bookmarks | int | 总收藏数 | 59 |
| total_view | int | 总查看数 | 251 |
| 图片 | bin | 所包含的插画图片 |  |
User
| 特征 | 类型 | 描述 | 示例 |
|---|---|---|---|
| user_id | int | 用户 id | 1257656 |
| username | String | 用户名 | zt*** |
Interaction
| 特征 | 类型 | 描述 | 示例 |
|---|---|---|---|
| user_id | int | 用户 id | 1257656 |
| illust_id | int | 画作 id | 115907684 |
| label | int | 0 表示浏览未收藏作为负样本,1 表示已收藏作为正样本 | 1 |
| create_time | timestamp | 行为产生的时间 | 2024-02-10 21:24:09 |
深度学习时代的特征工程

特征类型及预处理
在深度学习时代,推荐系统对原始输入数据的有效预处理至关重要。深度学习模型通常只能处理向量类型的数据,因此我们必须对不同类型的特征采取巧妙的处理策略。例如,对于连续数值类型的特征,如年龄、受欢迎程度等,我们常常采用归一化或分桶的方式,以保持数据分布一致性。而对于类别类型特征,如性别、职业等,我们可以选择映射为 One-Hot 编码或者使用 Hash 分桶进行处理,将其转换为模型可接受的向量形式。
在处理同为连续数值类型的 ID 类与统计类特征时(如收藏数、浏览数),考虑到它们可能存在分布上的差异,我们可以采用对数变换等方式,以抵消长尾效应,更好地反映其重要性。此外,结合场景先验知识也是关键的一环。以插画推荐场景为例,我们可能通过观察调整收藏数的阈值,超过一定阈值的收藏数可能表明画作足够优秀,而高于该阈值并不一定代表画作更加精美,因此对这个阈值进行分桶处理。
为了保持训练与预测时的分布一致,特别是在处理递增的 ID 值时,我们采用了 hash 桶的方式。通过定义预估较大的桶,确保包含特征取值范围,将 ID 值转换为 One-Hot 向量,然后通过全连接的嵌入层进行处理,以保持 ID 特征的个体性。这些巧妙的预处理策略有助于提高模型的泛化能力,确保推荐系统在深度学习时代更好地适应不同类型的特征。
| 特征 | 预处理方式 | 理由 |
|---|---|---|
| illust_id 、artist_id 、user_id | hash 分桶后 onehot | |
| tags 、username | hash 分桶后 onehot | |
| width 、height | 等频分桶 | |
| sanity_level 、restrict 、x_restrict | 直接映射 onehot | |
| total_bookmarks 、total_view | 每个特征分别处理成等频分桶与先验知识分桶 |
预训练特征抽取模型
在现代多媒体场景中,涵盖了各种非结构化数据,如文本、图像、音频等,这些数据通常难以通过传统结构化方法有效处理。这类数据蕴含着丰富的语义和信息,对于提升推荐系统的个性化和准确性至关重要。因此,我们需要对这些非结构化数据进行信息抽取,将其转化为特征向量,以便供推荐模型使用。在现代场景中,通常会应用深度学习相关技术来构建这种内容特征抽取模型,将深度神经网络( DNN )作为表征学习的工具。
深度学习时代强调了表征学习( Representation Learning )的重要性。深度学习模型通过多层次的神经网络学习输入数据的多层次、抽象的表示,这些表示又被称为嵌入( Embedding )。这样的嵌入具有强大的能力,能够捕捉输入数据中的丰富特征和模式,使得模型更深入地理解和处理输入数据。因此,深度学习模型将推荐算法从传统的"精确匹配"范式逐渐转变为"模糊查找"的新范式。通过嵌入学习,模型能够以更高层次的理解进行推荐。
相较于一般的特征,嵌入的维度更为丰富,描述的是在一个嵌入空间中的一个向量。这种嵌入向量的特性使得相似的物品在空间中距离更为接近,从而更准确地刻画物品之间的关系。引入 Embedding 技术后,推荐系统不仅可以精确匹配已知的信息,还能够在未曾见过的用户或物品上,通过 Embedding 的相似性提供合理的推荐,极大地增强了模型的泛化能力。在现代多媒体场景中,通过表征学习和 Embedding 技术,推荐系统能够更全面、更深入地理解用户和物品之间的关系,从而提高推荐效果。
由于以下论文中涉及了特征抽取的步骤,因此在此仅简要说明:
图片语义特征抽取
以图片到文本标签预测为代理任务,采用了 resnet101 作为骨干模型。该模型在训练中拟合了多类多标签的文本标签,然后通过去除预测头得到了图片的语义特征编码器。

作画质量特征抽取
为了量化图片的作画质量,采用了基于旧画作的收藏数、浏览数以及年龄分级的多任务模型。同样使用了 resnet101 作为骨干模型,该模型通过预测收藏数、浏览数以及年龄分级三个数值类型分桶后的结果,实现了对作画质量的特征抽取。
为了提高工程上的便利性,建议在打包模型时添加一个 base64 解析层。这样,在对 TensorFlow Serving 进行请求时,客户端只需要将图片二进制数据进行 base64 编码,并将其作为请求体的一部分,从而简化客户端构造样本的难度。
class Base64DecoderLayer(tf.keras.layers.Layer):
def __init__(self, target_size):
self.target_size = target_size
super(Base64DecoderLayer, self).__init__()
def byte_to_img(self, byte_tensor):
byte_tensor = tf.io.decode_base64(byte_tensor)
imgs_map = tf.io.decode_image(byte_tensor,channels=3)
imgs_map.set_shape((None, None, 3))
img = tf.image.resize(imgs_map, self.target_size)
img = tf.cast(img, dtype=tf.float32) / 255
return img
def call(self, input, **kwargs):
with tf.device("/cpu:0"):
imgs_map = tf.map_fn(self.byte_to_img, input, dtype=tf.float32)
return imgs_map
model = keras.models.load_model('/path/to/model', compile=False)
inputs = tf.keras.layers.Input(shape=(), dtype=tf.string, name='b64_input_bytes')
x = Base64DecoderLayer([512,512])(inputs)
x = model(x)
base64input_model = keras.Model(inputs=inputs, outputs=x)
动漫领域文本特征抽取
为了更好地抽取动漫领域文本特征,我们构建了多角度的文本对数据集。在此基础上,使用了通用的Sentence-Transformers,并对其进行微调。通过这样的方法,得到了更适用于动漫领域的文本特征。

文本模型的输入需要对语句进行分词以及映射,java 端可以使用 ai.djl.huggingface.tokenizers.Encoding 实现
@Component
public class SentenceTransformersTokenizer {
HuggingFaceTokenizer tokenizer;
@PostConstruct
public void init() throws IOException {
//HuggingFaceTokenizer.builder().
tokenizer = HuggingFaceTokenizer.newInstance(new ClassPathResource("tokenizer/SentenceTransformersTokenizer.json").getInputStream(), null);
}
public Encoding encode(String sentence) {
return tokenizer.encode(sentence);
}
public Encoding[] encodeList(List<String> sentence) {
return tokenizer.batchEncode(sentence);
}
}
@Data
public class TFServingTagFeatureExtractReq implements TFServingReq {
private final static String MODEL_NAME = TFServingModelInfo.ACGVOC_2_VEC;
private Encoding encode;
private Boolean batching;
private Encoding[] encodeArray;
private final static String pre = "{\"instances\": [";
private final static String pos = "]}";
@Override
public String getModelName() {
return MODEL_NAME;
}
@Override
public String getReqBody() {
if (batching) {
final StringBuilder body = new StringBuilder(pre);
for (int i = 0; i < encodeArray.length; i++) {
body.append("{\"input_ids\": " + Arrays.toString(paddingOrTruncate(encodeArray[i].getIds())) + ", \"attention_mask\": " + Arrays.toString(paddingOrTruncate(encodeArray[i].getAttentionMask())) + "},");
}
body.deleteCharAt(body.length() - 1);
body.append(pos);
return body.toString();
}
return "{\"instances\": [{\"input_ids\": " + Arrays.toString(paddingOrTruncate(encode.getIds())) + ", \"attention_mask\": " + Arrays.toString(paddingOrTruncate(encode.getAttentionMask())) + "}]}";
}
public long[] paddingOrTruncate(long[] input) {
final long[] result = new long[128];
if (input.length < 128) {
System.arraycopy(input, 0, result, 0, input.length);
} else {
System.arraycopy(input, 0, result, 0, 127);
result[127] = input[input.length - 1];
}
return result;
}
@Override
public TypeReference getRespType() {
return new TypeReference<Predictions<Float[]>>() {
};
}
public TFServingTagFeatureExtractReq(Boolean batching, Encoding encode) {
this.encode = encode;
this.batching = batching;
}
public TFServingTagFeatureExtractReq(Boolean batching, Encoding[] encodeArray) {
this.batching = batching;
this.encodeArray = encodeArray;
}
}
new TFServingTagFeatureExtractReq(false, sentenceTransformersTokenizer.encode(sentence))
特征维护工程细节
tensorflow 中的预处理层
def build_input(input_config):
feature_input = []
feature_map = {}
input_map = {}
embedding_layer_map = {}
hash_layer_map = {}
# 构建连续数值型特征输入
for num_feature in input_config.get('num', []):
layer = tf.keras.Input(shape=(1,), dtype=num_feature['dtype'], name=num_feature[
'feature'])
input_map[num_feature['feature']] = layer
feature_input.append(layer) # tf.feature_column.numeric_column(num_feature['feature']))
feature_map[num_feature['feature']] = layer
# 构建分类特征输入
for cate_feature in input_config.get('category', []):
layer = layers.Input(shape=(1,), dtype=cate_feature['dtype'], name=cate_feature['feature'])
input_map[cate_feature['feature']] = layer
# 是否数字型
if cate_feature.get('num_tokens') is None:
if cate_feature['embed_layer_name'] is None:
embed_layer = layers.StringLookup(vocabulary=cate_feature['vocabulary'], output_mode="one_hot",
num_oov_indices=0)
else:
if embedding_layer_map[cate_feature['embed_layer_name']] is None:
embed_layer = layers.StringLookup(vocabulary=cate_feature['vocabulary'], output_mode="one_hot",
name=cate_feature['embed_layer_name'],
num_oov_indices=0)
embedding_layer_map[cate_feature['embed_layer_name']] = embed_layer
else:
embed_layer = embedding_layer_map[cate_feature['embed_layer_name']]
layer = embed_layer(layer)
input_dim = len(cate_feature['vocabulary'])
else:
if cate_feature.get('embed_layer_name', None) is None:
embed_layer = layers.CategoryEncoding(num_tokens=cate_feature['num_tokens'], output_mode="one_hot")
else:
if embedding_layer_map.get(cate_feature['embed_layer_name']) is None:
embed_layer = layers.CategoryEncoding(num_tokens=cate_feature['num_tokens'], output_mode="one_hot",
name=cate_feature['embed_layer_name'])
embedding_layer_map[cate_feature['embed_layer_name']] = embed_layer
else:
embed_layer = embedding_layer_map[cate_feature['embed_layer_name']]
layer = embed_layer(layer)
input_dim = cate_feature['num_tokens']
# 是否需要 embedding
# if cate_feature.get('embedding_dims') is not None:
# layer = layers.Dense(cate_feature['embedding_dims'], use_bias=False)(layer)
feature_input.append(layer)
feature_map[cate_feature['feature']] = layer
# 需要 hash 分桶的特征
for hash_feature in input_config.get('hash', []):
layer = tf.keras.Input(shape=(1,), dtype=hash_feature['dtype'], name=hash_feature['feature'])
input_map[hash_feature['feature']] = layer
if hash_layer_map.get(hash_feature['hash_layer_name']) is None:
hash_layer = layers.Hashing(num_bins=hash_feature['num_bins'], output_mode='one_hot',
name=hash_feature['hash_layer_name'])
hash_layer_map[hash_feature['hash_layer_name']] = hash_layer
else:
hash_layer = hash_layer_map[hash_feature['hash_layer_name']]
layer = hash_layer(layer)
if hash_feature.get('embedding_dims') is not None:
if embedding_layer_map.get(hash_feature['embed_layer_name']) is None:
embed_layer = layers.Dense(hash_feature['embedding_dims'], use_bias=False,
name=hash_feature['embed_layer_name'])
embedding_layer_map[hash_feature['embed_layer_name']] = embed_layer
else:
embed_layer = embedding_layer_map[hash_feature['embed_layer_name']]
layer = embed_layer(layer)
feature_input.append(layer)
feature_map[hash_feature['feature']] = layer
# 连续数值分桶
for bucket_feature in input_config.get('int_bucket', []):
layer = tf.keras.Input(shape=(1,), dtype=bucket_feature['dtype'], name=bucket_feature['feature'])
input_map[bucket_feature['feature']] = layer
layer = layers.Discretization(bin_boundaries=bucket_feature['bin_boundaries'],
output_mode='one_hot', )(layer)
if bucket_feature.get('embedding_dims') is not None:
embedding = layers.Dense(bucket_feature['embedding_dims'], use_bias=False)
layer = embedding(layer)
feature_input.append(layer)
feature_map[bucket_feature['feature']] = layer
for dense_feature in input_config.get('dense', []):
layer = tf.keras.Input(shape=(dense_feature['dim'],), dtype=dense_feature['dtype'],
name=dense_feature['feature'])
input_map[dense_feature['feature']] = layer
feature_input.append(layer)
feature_map[dense_feature['feature']] = layer
cross_cate_map = {}
return feature_input, feature_map, input_map
画作特征维护
画作特征的维护采用了异步的方式。在需要的画作特征不存在时,将记录该需求到队列中,并由单独的线程负责更新和存储这些特征。这种异步的特征维护机制能够提高系统的响应速度且将维护过程与查询过程解耦,从而提升整体的性能和用户体验。
在查询时,由于向量浮点特征通常具有较大的维度,因此存储在 MySQL 中时选择使用像 BLOB 等大对象类型。这些大对象类型通常存储在 MySQL 的外部 BLOB 页中,需要额外的 IO 操作。为了更有效地处理这些向量浮点特征,最好采用键值数据库( KV 数据库)进行缓存处理。这样的架构能够提高查询效率,减少访问行外存储的 IO 开销。
多路召回
双塔召回
双塔结构召回是一种经典的向量化召回方案,其关键在于通过 loss 的引导实现用户 Embedding 和物品 Embedding 在同一向量空间的对齐。这种对齐使得用户向量能够直接检索相关的物品,使得两种异质对象在同一向量空间中得到对齐。
在本场景中,采用了 Point wise 建模方式,即与排序模型使用相同的建模目标,但样本构成方式不同。尽管 Point wise 建模方式在工程上更为便利,但实际上,List wise 建模方式对于召回来说可能是更好的选择。以分类为目标学习,相比于预估精确分数,List wise 更为简单且容易实现泛化性。然而,List wise 的工程难度相对较大。简化的方式可能会将其转化为以 batch 内其他样本作为负样本的形式,但这样做可能会导致某个正样本在这个 batch 中被错误地认为是负样本。Pair wise 建模也是一种可选方案,将在下文的图召回中应用。Point wise 建模方式也有其好处,它将召回和排序的 loss 统一,使得优化目标一致,有利于减少召回模型与排序模型预测结果相冲突的情况。
在构建数据集时,使用用户收藏画作以及最终曝光画作作为正样本,采用了随机采样与热门采样结合的方式进行负样本构造。在向数据集表进行插入时,采用了特殊的插入策略,先以 insert ignore 的方式插入负样本,使用用户 id 与画作 id 联合主键,随后采用 replace into 的方式插入正样本,以确保正样本可以覆盖负样本的需求。
图召回
参考了 Pinterest 公司发表的《 Graph Convolutional Neural Networks for Web-Scale Recommender Systems 》论文,基于用户与画作二部图,来获取画作表征。和原论文不同的是,我们采用了用户会话窗口来构造正样本,即在用户连续交互的时间区间内,每个画作都随机抽取窗口内的样本作为正样本。依托于tfgnn库,构造训练出的模型可以在 tf-serving 上部署并对外提供服务。
在得到画作表征以后,同样参考 Pinterest 公司《 PinnerSage Multi-Modal User Embedding Framework forRecommendations at Pinterest 》论文,对用户收藏画作特征向量进行层次化聚类后,将每个簇的 Medoids 来作为用户特征向量,以此实现 u2i 的召回通路。
协同过滤召回
一种常规的召回方式,计算时需要拉取全量交互行为数据。对于每个用户,计算得到相似用户列表。在实际的召回过程中,根据相似程度作为因子,从相似用户中拉取不同数量的收藏画作。
业务类型召回
- 关注画师新作
- 热门作品
-
近期搜索词
- 直接使用 ElasticSearch 搜索(按照收藏排序以及按照日期排序)召回
- 获得特征向量后使用向量检索引擎检索近似词,再使用 ElasticSearch 搜索召回
-
近期收藏画作
- 获得三种特征向量后使用向量检索引擎检索相似画作召回
- 检索到画师,后近似于关注画师新作的召回
- ...
工程细节
多路召回时,为每一路召回建立独立的小批次缓存。在总的召回模块进行合并结果时,按照多路归并的算法,依次取每一召回通路的头部结果。
排序
由于内容和论文大幅度重叠,该章节仅占位( arxiv 链接: https://arxiv.org/abs/2402.10381 )
重排
ddp 算法及其滑动窗口版本 java 实现(代码过长,v2ex 放不下,请前往 github 看 md ),参考 https://github.com/laming-chen/fast-map-dpp 、https://github.com/cmzdandan/dpp
A/B 测试与指标监控
暂无
第 1 条附言 · 2024 年 2 月 20 日
觉得有帮助的话请给 repo 点个 star 感谢🙏 https://github.com/OysterQAQ/ACG2vec
 |
1
mingge2333 2024 年 2 月 20 日
很有意思, 会公开模型下载地址吗
|
 |
2
OysterQAQ OP @mingge2333 推荐主体模型权重和业务强相关,没有公开的意义。特征抽取模型都在 acg2vec 里了。推荐主体模型的结构会公开
|
 |
3
0o0O0o0O0o 2024 年 2 月 20 日
OP 一直给我一种努力学习就是为了更好地看番看本的感觉
|
|
4
OysterQAQ OP @0o0O0o0O0o 还真是,毕竟也是少有的坚持了十几年的爱好了
|
 |
5
qq135449773 2024 年 2 月 21 日
非常好的文章,解答了之前的许多疑惑。
谢谢分享! |
|
6
OysterQAQ OP @qq135449773 👏有帮助就好
|
 |
7
charslee013 2024 年 2 月 21 日
给生蚝大佬点赞👍了
|
|
8
OysterQAQ OP @charslee013 😗感谢感谢
|
 |
9
hahiru 2024 年 2 月 22 日
点个赞
|
 |
10
yqt 2024 年 2 月 22 日 via Android
很不错,面试可以聊很多细节的项目哈哈
|
 |
12
Asfy 2024 年 2 月 22 日
为楼主实践精神点赞
|
 |
13
sunziren 2024 年 2 月 23 日
哇哦,太牛了
|
 |
14
GoRoad 2024 年 2 月 23 日
带佬 太猛了
|
 |
16
shm7 2024 年 2 月 26 日
关于为二次元图片构建推荐系统这件事
|
 |
18
momocraft 2024 年 2 月 27 日
太厉害了
|
 |
19
xieren58 2024 年 3 月 1 日
太厉害了
|
 |
20
levywang 2024 年 3 月 5 日
越来越 6 了 老铁
|