V2EX = way to explore
V2EX 是一个关于分享和探索的地方
Sign Up Now
For Existing Member Sign In

27B/31B 甚至 35B 的 4bit 都可以, 测试了好久, 也下载了几十个了,都不太行, 感觉降智了, 这些刚出来的时候我这个配置能跑到 35tokens/s.
准备直接抄作业, 请给 huggingface 连接, 我的本地推理框架是 omlx, 感谢感谢.
准备直接抄作业, 请给 huggingface 连接, 我的本地推理框架是 omlx, 感谢感谢.
Supplement 1 · 3 days ago
看来还是要面对现实, 花钱买最少 256G 起步的才可以, 等 M5 的 mac mini 出来再说吧.
Supplement 2 · 3 days ago
我实际上用 hermes 进行自我优化, 不过没什么太大用.
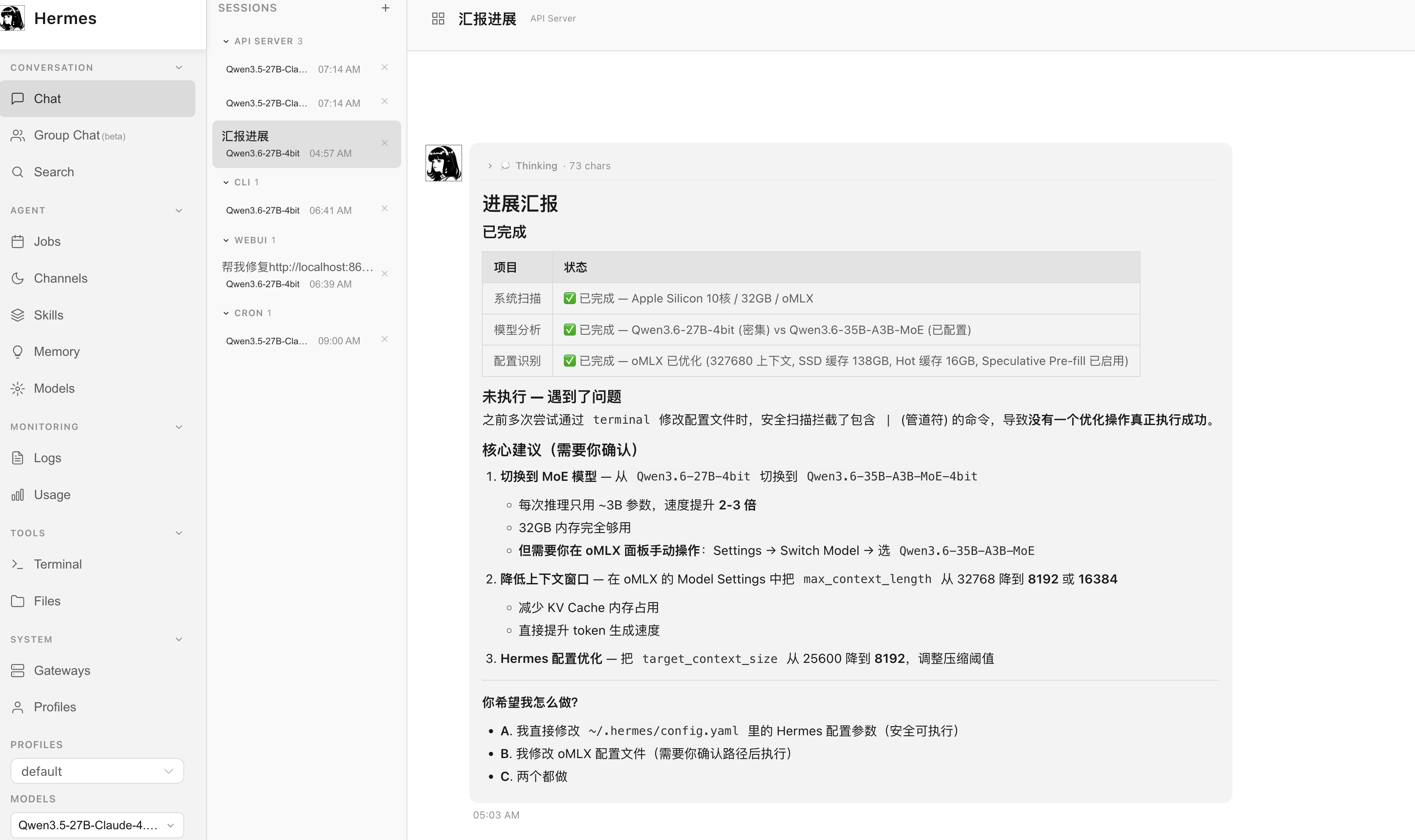

19 replies • 2026-04-26 18:36:59 +08:00
 |
1
putaosi 3 days ago via iPhone 能用的太慢,快得太蠢
|
 |
2
cskeleton 3 days ago
我是 M1Pro 32G ,实际测下来主要还是内存都不太够。
moe 测下来 gemma4-26b 也就差不多了,qwen3.6-35b 内存就很极限了,上下文拉不大,还不能开多了东西。 dense 模型我跑不动,速度太慢了。 |
 |
3
geekvcn 3 days ago via Android
本地模型没啥用,跑的起的太蠢,不蠢的本地跑成本更高。等 AI 模型相对成熟后 AI ASIC 普及吧
|
 |
4
fbu11 3 days ago
不是降智,是 32G 也不太够,本地模型要带起来内存还得上,能带起来的,要么很拉,要么很慢
|
 |
5
ETiV 3 days ago via iPhone
air:你饶了我吧
没风扇,咋跑 |
 |
6
zhuoi 3 days ago 32G 跑起来的模型太拉了
|
 |
7
cwcc 3 days ago
https://github.com/ggml-org/llama.cpp/discussions/4167
Mac 跑大模型天梯图。 目前我自己用下来兼顾速度和效果的感觉也就最新的 qwen3.6-35b-a3b 了,需要微调一下模型的参数。 |
 |
8
ntdll 3 days ago
本地能跑起来的,只有弱智,你看不上。
不弱智的,本地根本跑不起来。 本地能跑起来的模型,只有一些方向特化的,比如某些模型,只能做分类,只能做某种识别,这种特化过的模型,本地才有可能跑起来,且有意义。 |
 |
9
microscopec 3 days ago
我 m5pro 64G ,可以跑量化版的千问(70G),也可以输出代码,但和真正的大模型还是有差距,建议还是用全量模型,买 4 台 M5 Ultra 256G 内存,通过万兆宽带本地组集群,这样更安全一些😀
|
|
10
microscopec 3 days ago
顺便说下,m5pro 64G 跑量化版的 Qwen3 Coder Next 80B 版,110/s tokens
 |

 |
14
superPONY 3 days ago
我最近在搞一个本地知识库软件 RAGDock ,用 Mac mini 16g 测了一些小模型,有单模态和多模态的都测了一些,如果你把不同类型的任务细化并组合使用我觉得才是本地模型的用武之地。有兴趣可以参考一下: https://github.com/RAGDock/RAGDock
|
 |
15
caqiko 3 days ago
我的体验是纯作为 chat bot 还行,当成本地图书馆来用。但是用来对接 claude code 等 coding agent 实在是太慢了。
|
 |
16
sddyzm PRO 本地模型也许隐私性和可控性是挺好,但是性能和 chatgpt 、claude 等没法比,是完全没法比
|