推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2031 天前的主题,其中的信息可能已经有所发展或是发生改变。
我们研发开源了一款基于 Git 进行技术实战教程写作的工具,我们图雀社区的所有教程都是用这款工具写作而成,欢迎 Star 哦
如果你想快速了解如何使用,欢迎阅读我们的 教程文档哦
前情回顾
在上篇教程爬虫养成记--顺藤摸瓜回首掏(女生定制篇)中我们通过分析网页之间的联系,串起一条线,从而爬取大量的小哥哥图片,但是一张一张的爬取速度未免也有些太慢,在本篇教程中将会与大家分享提高爬虫速率的神奇技能——多线程。
慢在哪里?
首先我们将之前所写的爬虫程序以流程图的方式将其表示出来,通过这种更直观的方式来分析程序在速度上的瓶颈。下面程序流程图中红色箭头标明了程序获取一张图片时所要执行的步骤。
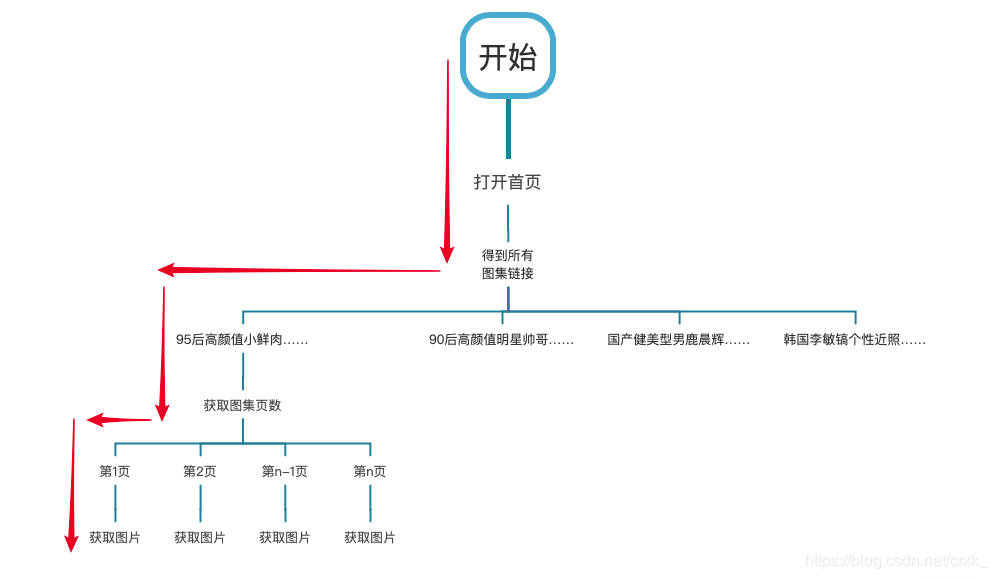 大多数的程序设计语言其代码执行顺序都是同步执行( JavaScript 为异步),也就是说在 Python 程序中只有上一条语句执行完成了,下一条语句才会开始执行。从流程图中也可以看出来,只有第一页的图片抓取完成了,第二页的图片才会开始下载…………,当整个图集所有的图片都处理完了,下一个图集的图片才会开始进行遍历下载。此过程如串行流程图中蓝色箭头所示:
大多数的程序设计语言其代码执行顺序都是同步执行( JavaScript 为异步),也就是说在 Python 程序中只有上一条语句执行完成了,下一条语句才会开始执行。从流程图中也可以看出来,只有第一页的图片抓取完成了,第二页的图片才会开始下载…………,当整个图集所有的图片都处理完了,下一个图集的图片才会开始进行遍历下载。此过程如串行流程图中蓝色箭头所示:
从图中可以看出当程序入到每个分叉点时也就是进入 for 循环时,在循环队列中的每个任务(比如遍历图集 or 下载图片)就只能等着前面一个任务完成,才能开始下面一个任务。就是因为需要等待,才拖慢了程序的速度。
这就像食堂打饭一样,如果只有一个窗口,每个同学打饭时长为一分钟,那么一百个学生就有 99 个同学需要等待,100 个同学打饭的总时长为 1+2+3+……+ 99 + 100 = 5050 分钟。如果哪天食堂同时开放了 100 个窗口,那么 100 个同学打饭的总时间将变为 1 分钟,时间缩短了五千多倍!
如何提速?
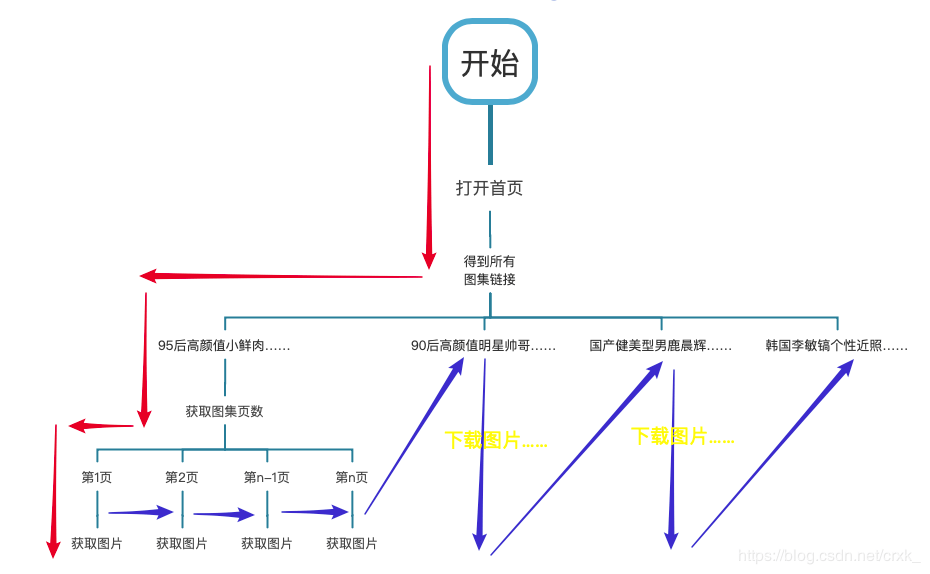
我们现在所使用的计算机都拥有多个 CPU,就相当于三头六臂的哪吒,完全可以多心多用。如果可以充分发掘计算机的算力,将上述串行的执行顺序改为并行执行(如下并行流程图所示),那么在整个程序的执行的过程中将消灭等待的过程,速度会有质的飞跃!
从单线程到多线程
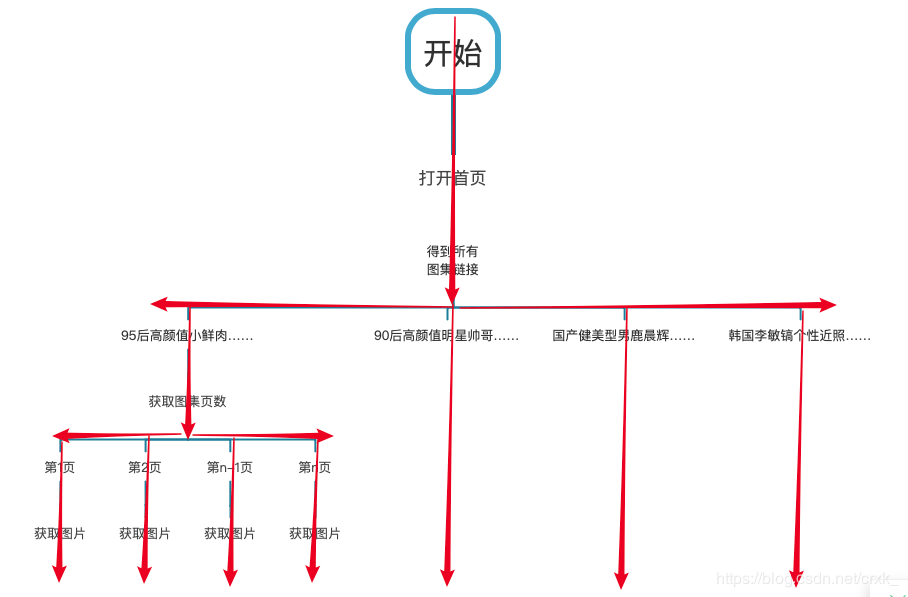
单线程 = 串行 从串行流程图中可以看出红色箭头与蓝色箭头是首尾相连,一环扣一环。这称之为串行。
多线程 = 并行 从并行流程图中可以看出红色箭头每到一个分叉点就直接产生了分支,多个分支共同执行。此称之为并行。
当然在整个程序当中,不可能一开始就搞个并行执行,串行是并行的基础,它们两者相辅相成。只有当程序出现分支(进入 for 循环)此时多线程可以派上用场,为每一个分支开启一个线程从而加速程序的执行。对于萌新可以粗暴简单地理解:没有 for 循环,就不用多线程。对于有一定编程经验的同学可以这样理解:当程序中出现耗时操作时,要另开一个线程处理此操作。所谓耗时操做比如:文件 IO 、网络 IO……。
动手实践
定义一个线程类
Python3 中提供了threading模块用于帮助用户构建多线程程序。我们首先将基于此模块来自定义一个线程类,用于消灭遍历图集时所需要的等待。
线程 ID
程序执行时会开启很多个线程,为了后期方便管理这些线程,可以在线程类的构造方法中添加 threadID 这一参数,为每个线程赋予唯一的 ID 号
所执行目标方法的参数
一般来说定义一个线程类主要目的是让此线程去执行一个耗时的方法,所以这个线程类的构造方法中所需要传入所要执行目的方法的参数。比如 handleTitleLinks 这个类主要用来执行getBoys() (参见文末中的完整代码)这一方法。getBoys() 所需一个标题的链接作为参数,所以在 handleTitleLinks 的构造方法中也需要传入一个链接。
调用目标方法
线程类需要一个 run(),在此方法中传入参数,调用所需执行的目标方法即可。
class handleTitleLinks (threading.Thread):
def __init__(self,threadID,link):
threading.Thread.__init__(self)
self.threadID = threadID
self.link = link
def run(self):
print ("start handleTitleLinks:" + self.threadID)
getBoys(self.link)
print ("exit handleTitleLinks:" + self.threadID)
实例化线程对象代替目标方法
当把线程类定义好之后,找到曾经耗时的目标方法,实例化一个线程对象将其代替即可。
def main():
baseUrl = "https://www.nanrentu.cc/sgtp/"
response = requests.get(baseUrl,headers=headers)
if response.status_code == 200:
with open("index.html",'w',encoding="utf-8") as f:
f.write(response.text)
doc = pq(response.text)
# 得到所有图集的标题连接
titleLinks = doc('.h-piclist > li > a').items()
# 遍历这些连接
for link in titleLinks:
# 替换目标方法,开启线程
handleTitleLinks(uuid.uuid1().hex,link).start()
# getBoys(link)
如法炮制
我们已经定义了一个线程去处理每个图集,但是在处理每个图集的过程中还会有分支(参见程序并行执行图)去下载图集中的图片。此时需要再定义一个线程用来下载图片,即定义一个线程去替换 getImg()。
class handleGetImg (threading.Thread):
def __init__(self,threadID,urlArray):
threading.Thread.__init__(self)
self.threadID = threadID
self.url = url
def run(self):
print ("start handleGetImg:" + self.threadID)
getPic(self.urlArray)
print ("exit handleGetImg:" + self.threadID)
改造后完整代码如下:
#!/usr/bin/python3
import requests
from pyquery import PyQuery as pq
import uuid
import threading
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'cookie': 'UM_distinctid=170a5a00fa25bf-075185606c88b7-396d7407-100200-170a5a00fa3507; CNZZDATA1274895726=1196969733-1583323670-%7C1583925652; Hm_lvt_45e50d2aec057f43a3112beaf7f00179=1583326696,1583756661,1583926583; Hm_lpvt_45e50d2aec057f43a3112beaf7f00179=1583926583'
}
def saveImage(imgUrl,name):
imgResponse = requests.get(imgUrl)
fileName = "学习文件 /%s.jpg" % name
if imgResponse.status_code == 200:
with open(fileName, 'wb') as f:
f.write(imgResponse.content)
f.close()
# 根据链接找到图片并下载
def getImg(url):
res = requests.get(url,headers=headers)
if res.status_code == 200:
doc = pq(res.text)
imgSrc = doc('.info-pic-list > a > img').attr('src')
print(imgSrc)
saveImage(imgSrc,uuid.uuid1().hex)
# 遍历组图链接
def getPic(urlArray):
for url in urlArray:
# 替换方法
handleGetImg(uuid.uuid1().hex,url).start()
# getImg(url)
def createUrl(indexUrl,allPage):
baseUrl = indexUrl.split('.html')[0]
urlArray = []
for i in range(1,allPage):
tempUrl = baseUrl+"_"+str(i)+".html"
urlArray.append(tempUrl)
return urlArray
def getBoys(link):
# 摸瓜第 1 步:获取首页连接
picIndex = link.attr('href')
# 摸瓜第 2 步:打开首页,提取末页链接,得出组图页数
res = requests.get(picIndex,headers=headers)
print("当前正在抓取的 picIndex: " + picIndex)
if res.status_code == 200:
with open("picIndex.html",'w',encoding="utf-8") as f:
f.write(res.text)
doc = pq(res.text)
lastLink = doc('.page > ul > li:nth-last-child(2) > a').attr('href')
# 字符串分割,得出全部的页数
if(lastLink is None):
return
# 以.html 为分割符进行分割,取结果数组中的第一项
temp = lastLink.split('.html')[0]
# 再以下划线 _ 分割,取结果数组中的第二项,再转为数值型
allPage = int(temp.split('_')[1])
# 摸瓜第 3 步:根据首尾链接构造 url
urlArray = createUrl(picIndex,allPage)
# 摸瓜第 4 步:存储图片,摸瓜成功
getPic(urlArray)
def main():
baseUrl = "https://www.nanrentu.cc/sgtp/"
response = requests.get(baseUrl,headers=headers)
if response.status_code == 200:
with open("index.html",'w',encoding="utf-8") as f:
f.write(response.text)
doc = pq(response.text)
# 得到所有图集的标题连接
titleLinks = doc('.h-piclist > li > a').items()
# 遍历这些连接
for link in titleLinks:
# 替换方法,开启线程
handleTitleLinks(uuid.uuid1().hex,link).start()
# getBoys(link)
# 处理组图链接的线程类
class handleTitleLinks (threading.Thread):
def __init__(self,threadID,link):
threading.Thread.__init__(self)
self.threadID = threadID
self.link = link
def run(self):
print ("start handleTitleLinks:" + self.threadID)
getBoys(self.link)
print ("exit handleTitleLinks:" + self.threadID)
# 下载图片的线程类
class handleGetImg (threading.Thread):
def __init__(self,threadID,url):
threading.Thread.__init__(self)
self.threadID = threadID
self.url = url
def run(self):
print ("start handleGetImg:" + self.threadID)
getImg(self.url)
print ("exit handleGetImg:" + self.threadID)
if __name__ == "__main__":
main()
性能对比

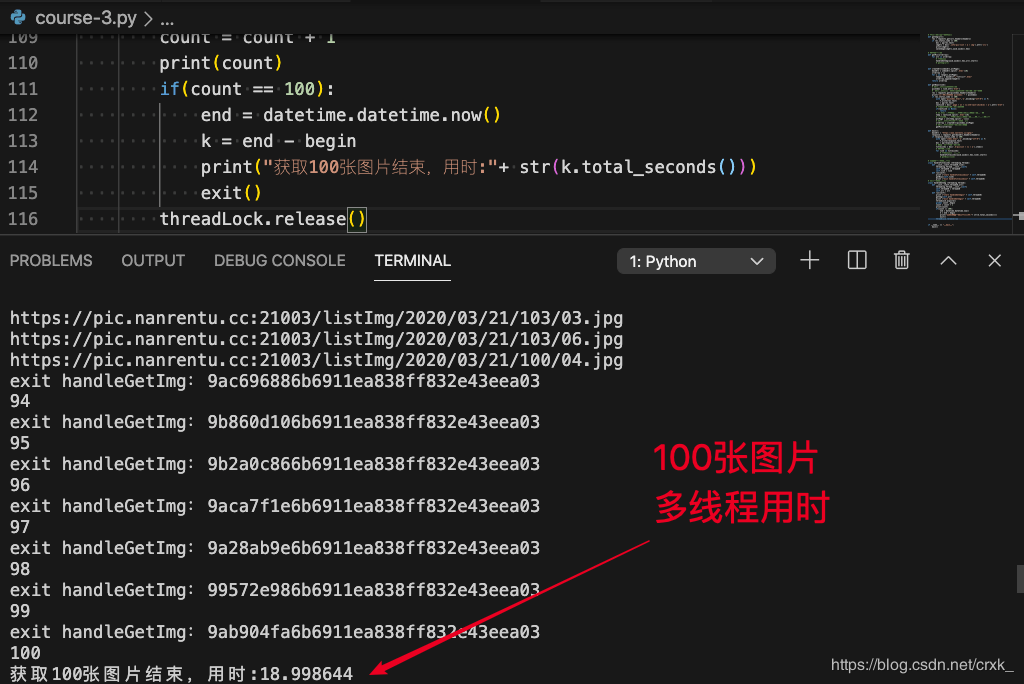
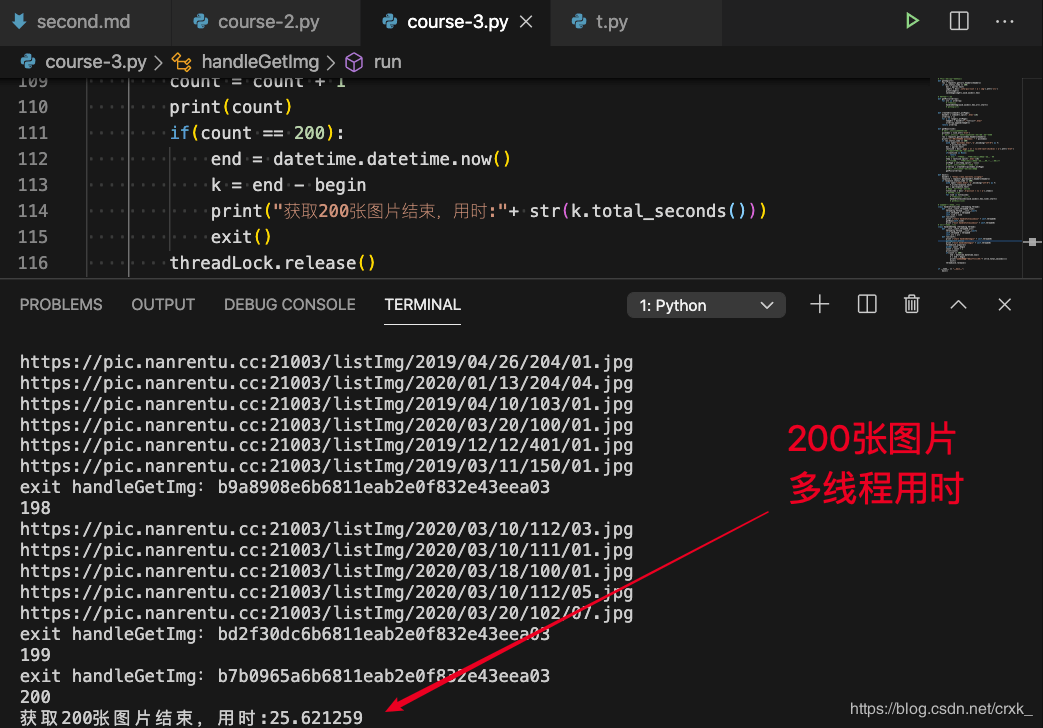
因为网络波动的原因,采用多线程后并不能获得理论上的速度提升,不过显而易见的时多线程能大幅度提升程序速度,且数据量越大效果越明显。
总结
至此爬虫养成记系列文章,可以告一段落了。我们从零开始一步一步地学习了如何获取网页,然后从中分析出所要下载的图片;还学习了如何分析网页之间的联系,从而获取到更多的图片;最后又学习了如何利用多线程提高程序运行的效率。
希望各位看官能从这三篇文章中获得启发,体会到分析、设计并实现爬虫程序时的各种方法与思想,从而能够举一反三,写出自己所需的爬虫程序~ 加油!🆙💪
预告
敬请期待爬虫进阶记~
想要学习更多精彩的实战技术教程?来图雀社区逛逛吧。
如果你觉得我们写得还不错,欢迎关注我们的公众号哦❤️
{kind=link}
 |
1
B1ankCat 2020-04-29 08:37:12 +08:00
小哥哥在哪里
|
 |
2
Marstin 2020-04-29 08:37:25 +08:00
推广节点?
|
 |
3
phytry 2020-04-29 09:29:42 +08:00
爬虫写的好~
|
 |
4
llsquaer 2020-04-29 10:40:30 +08:00
一个事情请教..线程安全的吗? 之前也用多线程..不想去手动加锁,,所以直接用的 queue 队列...你这种写法感觉更爽一些..但是还不明白其中的原理. 举个例子: 比如下载图片,他会自动加载 100 个线程?(图片有 100 个链接的情况)
|
 |
5
sxfscool 2020-04-29 12:35:14 +08:00 via Android
入狱教程
|
 |
7
crella 2020-04-29 13:20:05 +08:00 via Android
数学是体育老师教的吗? 100 个同学打饭总时长为 5050 分钟>83 小时>3 天,这饭可真够香
|
|
8
crella 2020-04-29 13:25:15 +08:00 via Android
@llsquaer 我记得以前看过文章,含 GIL 的脚本解释器都是线程安全的,比如 CPython 和 MRI 。但是 Jython 和 Jruby 依靠 Java,在 windows 上也支持多核执行。不知道 PyPy 是什么情况
|
 |
9
huan1043269994 OP @crella 这里不是算实际等待时间,是算所有人的一个总消耗,即如果有一百人,等待一分钟就等待了 100 分钟
|
|
10
crella 2020-04-30 22:41:47 +08:00
@crella 我上面说 GIL 能够保证线程安全,至少在 ruby 上不成立。见 https://xguox.me/concurrency-in-ruby.html/,页面内搜索:'GIL 并不能完全阻止竞争条件的发生'
|