
背景
之前一直以为 MySQL 的多表关联查询语句是首先对 FROM 语句的前两张表执行笛卡尔积,产生一张虚拟表,然后使用 ON 过滤和 OUTER JOIN 添加外部行,再使用过滤后的虚拟表跟第三张表进行笛卡尔乘积,重复执行上述步骤。下面是从网上搜到一些比较热门的 SQL 执行顺序的文章,大家应该很熟悉吧,尤其是下面那张鱼骨图。
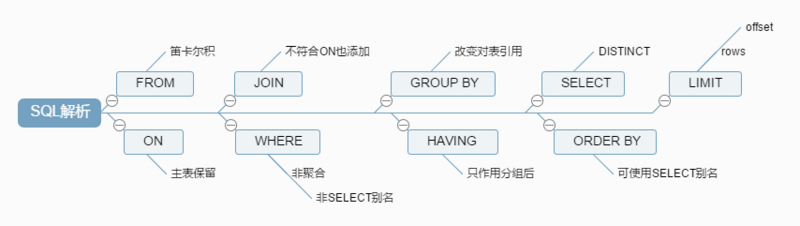 摘自:步步深入:MySQL 架构总览->查询执行流程->SQL 解析顺序
摘自:步步深入:MySQL 架构总览->查询执行流程->SQL 解析顺序
 摘自:
摘自:问题描述
最近由于工作需要,对 SQL 查询性能要求比较高,阅读了《高性能 MySQL (第 3 版)》查询优化的相关章节,在“6.4.3 查询优化处理”章节有这样一句话:
MySQL 对任何关联都执行嵌套循环关联操作,即 MySQL 先在一个表中循环读取单条数据,然后再嵌套循环到下一个表中寻找匹配的行,依次下去,直到找到所有表中匹配的行为止。然后根据各个表匹配的行,返回查询中需要的各个列。MySQL 会尝试在最后一个关联表中找到所有匹配的行,如果最后一个关联表无法找到更多的行以后,MySQL 返回到上一层次关联表,看是否能够找到更多的匹配记录,依次类推迭代执行。
于是对之前的认识产生怀疑,如果所有关联都是嵌套循环关联查询的话,只有当没有任何过滤条件时两张表才会产生笛卡尔乘积,而且这个笛卡尔乘积是一个结果,并不是关联查询的步骤,而且如果两张几十万、上百万的表进行笛卡尔乘积,这数据量有点巨大了。。。在 MySQL 的官方手册 中也印证了嵌套循环操作: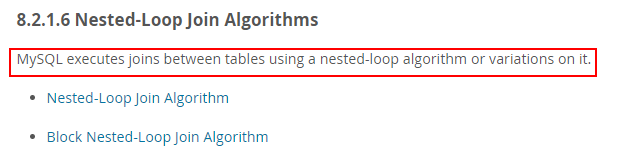
在博客园找到 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(一) 这篇博客对上述笛卡尔乘积也有同样的疑问,而且给出了实际的案例分析,个人比较认同该博主的观点。里面有这样一个案例:
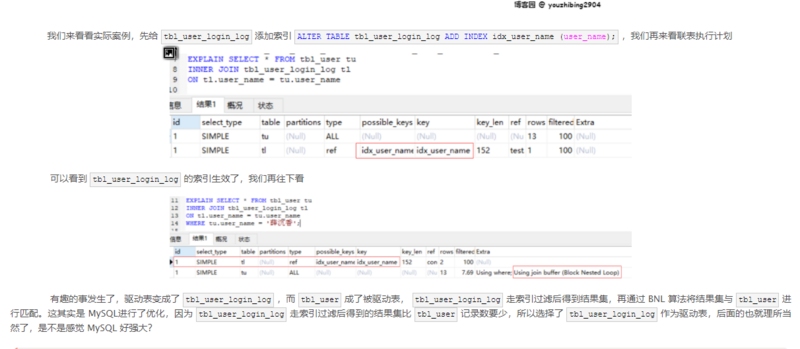
从这个案例可以看出当查询优化器使用 Index Nested-Loop 即索引嵌套循环,WHERE 条件首先通过索引过滤驱动表的数据然后再关联被驱动表,更加印证了 WHERE 不是在两表生成笛卡尔乘积后才进行过滤的。如果从“嵌套循环关联”的角度看,之前的关联表先生成笛卡尔乘积再进行过滤的理论是站不住脚的。
那么问题就是这种“笛卡尔乘积过滤”的理论有什么历史原因吗,为什么网上的文章大部分都是这种,还是我对“嵌套循环查询”有误解? 我相信有不少小伙伴跟我一样的疑惑吧,还望 V 站大佬给指点迷津。




