
魔改 Alfred Youdao Translator 实现翻译短语同时一键添加至 Logseq Flashcards
wfnuser · 2023 年 1 月 8 日 · 2676 次点击这是一个创建于 1131 天前的主题,其中的信息可能已经有所发展或是发生改变。
原文链接 感谢关注~
写在前面
这篇文章是微扰酱新年的第一篇推文,源于下午对 Alfred Youdao Tanslator workflow 的一次魔改。最终实现了在翻译某些英文短句的同时,可以一键添加到 Logseq Flashcards 中的效果。对这件事本身感兴趣的同学也可以把这个文章当作一个简单的教程阅读。
事实上,这次魔改的胜利是来之不易的,调试花了许多时间,以至心情一度不佳;好在峰回路转,作为新年的第一篇文章,也是期望今年一切顺利吧。
正文
工具哲学这个词我最早是从哪里听到的,已经无从考证。印象中是因为有朋友曾经告诉过我,谷歌的内部开发工具非常领先,其员工也特别善于引入或者创造出各种好用的工具以提高自己和团队成员的工作效率。我想用中国的古话来说,自然就是 “工欲善其事,必先利其器”。

程序员与工具
事实上,程序员们在日常工作生活中使用到“工具”的机会应该是较常人更多的。毕竟对于其他行业的白领来说,可能并不会特别地将 Word\Excel\Power Point 等办公软件称为工具,他们更像是工作的必需品,可替代选项也非常局限;而随着消费主义的兴起和生产力的不断发展,普通人可能也更难在日常生活中真地“创造”出什么特别的工具,因为在淘宝上下单显然是更经济的方式;使用这些工具的方式也更多的源自于别人的灌输,而不是独立的创新。
但对于软件有更深入理解的相关从业人员来说,无论是定制软件工具的能力,或是程序员的本职工作可能就是创造工具这样天然的秉性,都让他们有更多地机会将工具发挥于工作中。写代码的时候各种脚手架、IDE 、语法检查工具、热编译工具等等,相信有软件开发经验的同学一定都不陌生;并且每个人配置和熟悉的开发环境可能都大相径庭。而大部分程序员来到新公司报到时第一件做的事情也通常是配置环境,我相信其中一半的努力应该就是为了将自己熟悉的工具悉数搬到这台新的电脑中。
| Software development stage | Inside Google | Outside Google |
|---|---|---|
| Identify feature or bug | Issue Tracker | GitHub issues, Jira |
| Read code | Code search | Your editor, OpenGrok, Hound, Sourcegraph |
| Test code | Blaze | A bit of the Wild West, but Bazel is gaining traction |
| Review code | Critique | GitHub PRs, Gerrit, Phabricator, Reviewable |
| Deployment | Borg | Kubernetes |
| Monitoring | Borgmon, Dapper, Viceroy | Prometheus, Grafana, Lightstep, Honeycomb, Sentry |
不过,如果你仔细审视一下这个现象,应该可以发现,对于软件从业者使用软件作为生产力工具这件事情上,也很难说,大部分从业者做的足够好了。因为除了每个程序员都会使用的工具,绝大部分从业者也没有真的在工具这件事情上做过足够的探索和贡献,当然,这本身是一个很高的要求;而最常见的工具使用理由是某个同事用着这个工具
docker-sync 的例子
比如,对于 docker 在 mac 系统上绑定磁盘文件同步过慢这个问题来说,docker-sync 这个工具被发明或者改进的过程中至少会碰到以下障碍。
- 1 )需求或者问题不能被发现。
- 2 )解决需求的思路不能被找到。
- 3 )解决需求的努力太大,令人却步。
其使用的过程中也会至少有两个障碍,分别是:
- 1 )无法发现用来解决当前需求的既有工具。
- 2 )学习该工具的成本过高,令人却步。

以我在工作中的经历为例,在我开始使用 docker-sync 之前,一直碰到代码在 docker 容器中编译速度显著慢于同事的情况,当时大部分同事使用的是虚拟机环境。于是首先我就有两个选择,一个是继续使用 docker ,另一个则是迁移到大部分同事的最佳实践中,采用虚拟机环境。选择后者显然意味着我可以直接借鉴同事的经验,但是却失去了我对 docker 非常欣赏的一些特性;那如果选择后者,我自然也就失去了继续研究这个问题本身,进而找到合适工具的机会。
但是即使在我选择了继续使用 docker 之后,很长一段时间里,我一直都选择了忍受这个问题;大部分时间里我在怀疑各种环境配置或者硬件配置的问题;而更妙的是,我只是陷入了一种并非无法忍受的痛苦,加上工作本身的压力,我并没有足够的意愿去真正解决这个问题。
当然,后来我终于在巧合之下发现了编译慢和磁盘绑定有着密切关系,并进而找到了问题的根源和一种不错的解决方案 docker-sync 。我想这个故事充分说明了,即使我深刻了解工具的重要性,在我真正开始找工具去解决问题之前,我会遇到多大的障碍。
而,如果你去看 docker-sync 的官方 issue 时,你也会发现它作为一款用户不多的软件,有一些 issue 并没有得到有效的解决,以至于我通过 brew 安装某个版本的 docker-sync 时,一直会碰到自动同步失败的问题。具体可以查看这个 issue。这应该也能充分论证,大部分工具使用者并没有充分的动机、能力或者时间去做哪怕仅仅是改良某个工具的努力。

而 docker-sync 的作者在开发这个工具之前,除了需要发现问题和有去解决这个问题的意愿之外,还需要有对 docker 工作原理的基本认识,对几种同步协议的清晰了解;这背后其实都是非常高的要求。收益当然也是巨大的,相信帮助了许多人解决了问题,该项目也在 github 上收获了 3k+ 的 star ;对我来说,使用了这个工具之后,每次跑全量测试至少节约了 20min ,每次编译则省去了 2/3 以上的时间,相对来说,我研究这个问题所花费的时间则是微不足道的。
通过 Alfred 工作流在 Logseq 中建立卡片
明白了工具的益处和使用或者发明他们的困难之后,作为有追求的程序员,我们自然也应该努力去克服这些困难,并学会发现各种可以通过工具去提高生产力的场景并进行实践。下面我以另一个例子来谈谈我的实践,以及我是如何克服前述的一些障碍的。
微扰酱最近一直在通过 logseq 实践卡片阅读法,在我今天阅读 the great Gatsby 的时候,突然想到要将一些书中的一些我不熟悉的地道英文表达记录到卡片中。这个过程比较简单的方式,当然是查询相关 phrase 的解释,并手动摘录到 logseq 中形成卡片。从单次操作来看,额外的成本是非常有限的,可能只需要花费 10s 不到即可完成;但是由于这显然会是一个高频操作,这样的时间开销是不能接受的。 所以,首先我们要建立的信仰就是,当一个重复操作会产生的时候,我们就必须去试着优化他;如果没有这样的信仰,则很容易陷入这个简单重复的时间陷阱中。另一方面,这也能说明,很多时候工具背后的需求并不是天然存在的;比如如果我没有采用卡片阅读法,也没有已经在使用 logseq 和 alfred 这样的工具,我当然也不会想到将一些 phrase 记录到卡片中的流程自动化的问题;所以另一个启示则是,如果你原本就更有意愿去提高效率或者使用工具,你也就会有更多使用或者改良其他工具的机会。这是关于需求点本身的问题。
那么具体如何解决这个自动化的问题呢?必不可少的,我们需要一些基本的知识储备。比如,在我的例子中,我需要经过一段时间对 logseq 的使用,并且我需要事先知道在 mac 系统上有一些创建自动工具流的工具,比如 alfred ;最后我需要一些基本的编程知识。这一块,想必只有相信长期主义了。
在我的例子中,通过使用搜索引擎和简单实验,我确认了在 logseq 中添加卡片只需要修改对应的 markdown 文件,了解了 alfred workflow 的基本使用,并且由于我最终对 YoudaoTranslator 这款 alfred 插件进行了魔改,我花费了一些时间了解了其工作原理并阅读了其源码。获得了这些信息之后,整个自动化的思路其实很快就确定了,但实践的过程依旧是非常艰难和痛苦的,下面我们描述一下整个过程:
首先,你需要安装 alfred 和 YoudaoTranslator 插件,并配置上自己在有道云上申请的 secret key ;这样你就可以快速的通过有道提供的 NLP 服务对任意英文文本进行中文翻译。
随后,就是痛苦的根源,你需要去了解 YoudaoTranslator 的工作原理,在你发现这个软件并没有留下良好的扩展空间之前已经会遇到不少问题,而当你发现这个事实之后,更需要进行相关代码的阅读、反复的魔改和实验。
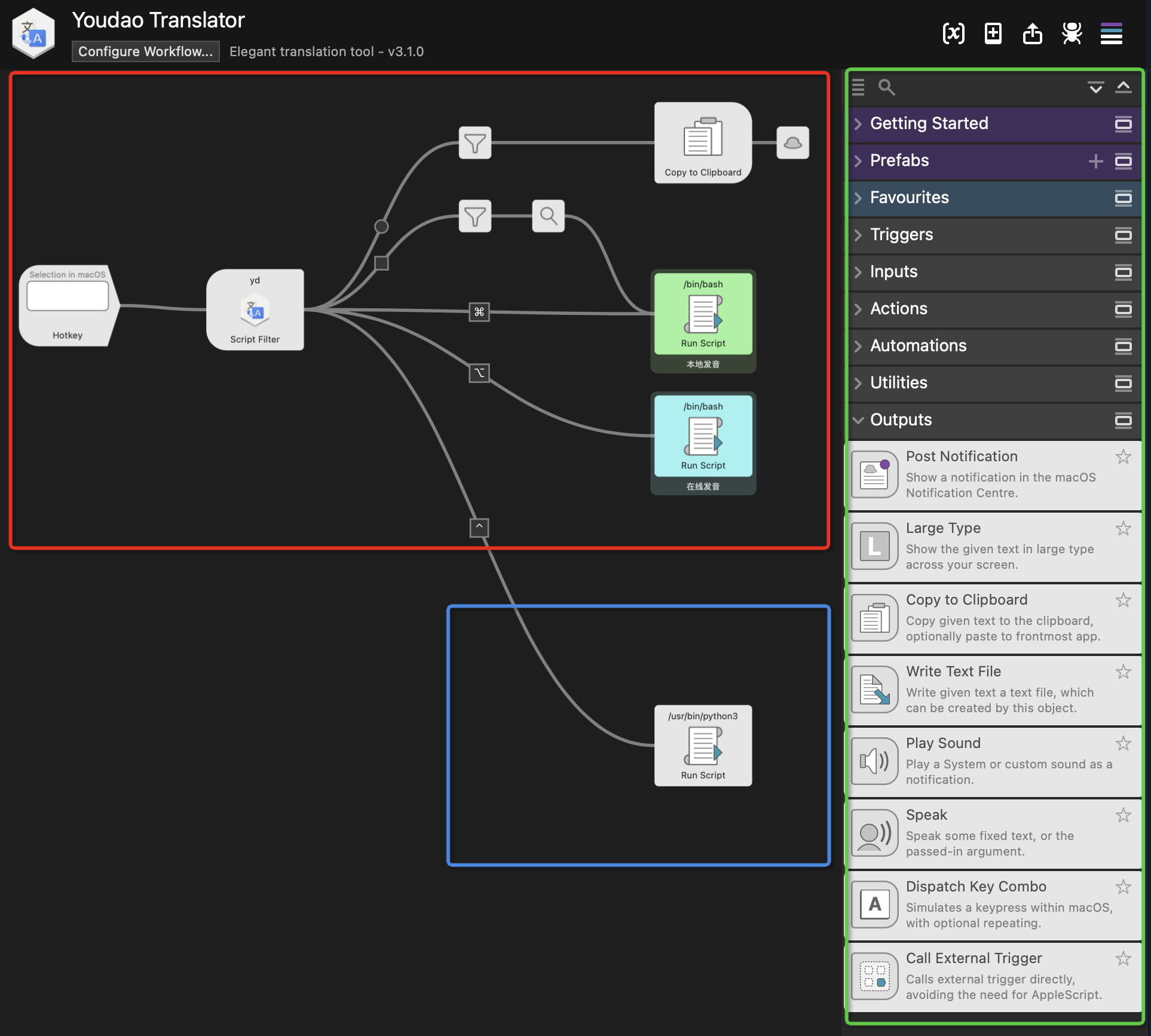
在上图中,红框里是 Youdao Translator 原生的 workflow ;绿框里则是许多你需要去了解的 workflow 的控制节点;蓝框内则是我们最后的成果,在其中我们写了一段脚本,使得最后我们可以在 Youdao Translator 中获取翻译结果之后,通过 ctrl+enter 即可实现对应 phrase 在 logseq 中卡片的建立。
这里我采用的手段比较 hack ,从本地插件目录中获取 Youdao Translator 的代码,在其中添加上 setCtrl 的分支,使得我们从 Script Filter 传到 Run Script 中的参数中同时包含了翻译前后的信息;而这件事是写死在 Youdao Translator 中的 js 脚本里的。我们的主要魔改如下,但这显然不是一个扩展性良好的方案,若是以后有机会自然要再处理这个问题。写这篇文章其实也起到了一个记录作用,万一在我下次升级软件之前仍然没有解决这个问题,可能就需要将这个过程再来一遍了;这本身也应该是一个被解决的问题,当然,我已经努力过了。
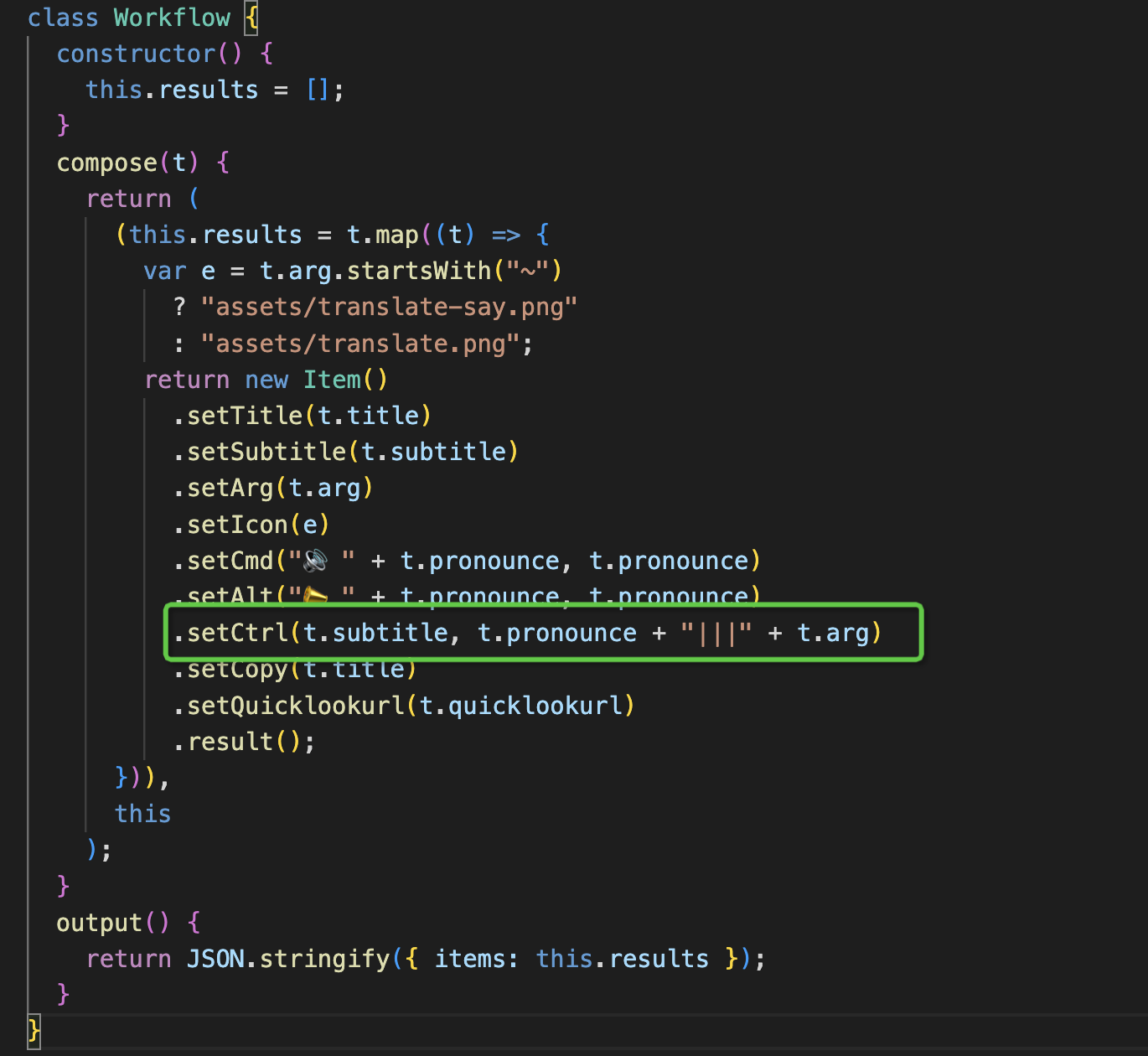
完成这这一步之后,我只需要在蓝框内实现下面的脚本即可大功告成了。
# -*- coding:utf-8 -*-
from __future__ import unicode_literals, print_function
import sys, os, io, subprocess
FILE=os.path.expanduser("/Users/huangqinghao/Workspace/wfnuser/MyLogseq/pages/english word list.md")
output = []
text = "{query}"
lines = text.split("|||")
if len(lines) < 2:
exit(0)
word = lines[0]
hint = lines[1]
output.append('- {} #card'.format(word))
output.append('\t- {}'.format(hint))
old_words = set()
with io.open(FILE, 'r', encoding='utf8') as fp:
for line in fp:
parts = line.split()
if line.startswith('-') and len(parts) > 1:
old_words.add(parts[1])
if word not in old_words:
with io.open(FILE, 'a', encoding='utf8') as fp:
fp.write('\n')
fp.write('\n'.join(output))
fp.write('\n')
在 python 脚本中,我们会遍历在 logseq 中的 word list ,确保新加入的 phrase 与已存在的没有重复;通过在 markdown 中增加 #card 标签,我们轻而易举的实现了将文本内容变成闪卡并在以后可以定期复习的功能。最后的效果如下:

其实直到最后我的预期目标终于跑通之前,过程完全谈不上愉快,也有好几次想要放弃;全靠反复告诉自己未来可以获得的收益和成就感才得以坚持。而当我最终第一次完成了对 alfred 工作流的定制时,确实也收获了不小的快感;并且对之后定制其他工作流也充满了兴趣。相信,如果多收获几次类似的正反馈,我对定制工具所产生的困难的忍受度也会自然变得更高。
下图为被 hack 的代码本来的样子,格式化之后还是可以改一改的。

小结
使用和创造工具是智人有别于直立人乃至南方古猿的重要体现。而在生产力高度发展的今天,人们可能很难有太多机会独立地在工具生产上做出开创性的工作,但是是否热衷以及擅长使用优秀的工具,是否能够将更多的工具组合起来以及发现可以被工具优化的空间依旧会对人们的学习生产效率产生巨大的影响。
而在前一段时间被 ChatGPT 震撼之后,我也更加觉得,未来肯定会有更多基础的工作将被人工智能替代;那么学会高效地和人工智能一起工作当然也会是很重要的能力。我想更善于使用工具的人,应该也会在这方面做的更好吧;这就是今天折腾一下午的所思所想,作为新年的第一篇文章,分享给大家。

 |
1
wensonsmith 2023 年 1 月 9 日
nice!
哈哈哈 |
 |
2
4ark 2023 年 1 月 9 日 via iPhone
写得不错
|
 |
3
wfnuser OP @wensonsmith 哈哈哈 竟然碰到了原作者! 说起来,确实感觉没有留出很好的扩展空间哦 不知道有没有更好的改法 要不我建个 issue 讨论一下~
BTW 大佬在 github 上贴的用户交流二维码已经过期了😂 可以加一下嘛 我的 wechat:wfnusee |
|
5
wensonsmith 2023 年 1 月 9 日
@wfnuser #3 加你啦! 之前没想过这方面的拓展
|
 |
6
luischow 2024 年 1 月 25 日
@wensonsmith 您好,已给您的项目 star+关注,交流群可以加下我下吗? wechat:373452759
感谢! |