
问大家一个关于使用 K8s 的 Service 做长连接负载均衡的问题
zhoudaiyu · 2023-01-18 20:41:38 +08:00 · 2602 次点击这是一个创建于 721 天前的主题,其中的信息可能已经有所发展或是发生改变。
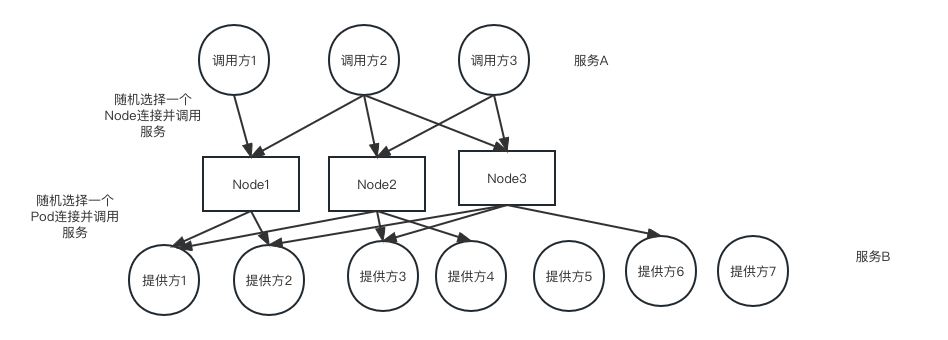
背景是我们有 2 个 K8s 集群,上面都运行着一些 tomcat 应用,这两个集群有互相调用的需求,因此需要暴露出 NodePort 供另外一个集群的 Pod 调用(因为不同集群的 Pod 间无法通过 Pod IP 直接访问),又为了保证跨集群调用的高可用性,需要提供多个 Node 供服务调用方随机选择。图里给了个例子,下面我用调用方 A (服务 A )调用服务 B 为例讲一下整个调用的流程,首先在服务启动的时候,提供方 B 的所有应用 POd 的 IP 会被注册到注册中心,服务 A 如果想调用服务 B 的某个 POd ( IP 是随机的),服务注册的客户端发现对方的 IP 是另外一个集群的,无法直接访问,因此将 IP 替换为另外一个集群的 Node IP+NodePort ( Node IP 也是随机选一个),这时请求就到了某台机器的 Service ,Service 会再次负载均衡一下连接到某个 POd ,但是由于用了 netty 的长连接,因此连接一旦建立,就不会再销毁了。因此,虽然单独看某台 Node 的负载到 Pod 上的链接是均衡的,但是在所有被随机到的 Node 来看,可能并不是那么均衡(特别是当连接建立的比较少的时候),因此就会造成有的提供方 Pod 被调用的比较多,有的比较少的问题。请问这种长连接情况下,如何能把负载做的均衡一点?
 |
1
idblife 2023-01-18 20:46:55 +08:00
node 前加一层 haproxy ?
|
 |
2
swulling 2023-01-18 20:47:12 +08:00 via iPhone
k8s 的 service 的负载均衡算法很固定,目前实现基本是 ipvs 。要想修改为适合长链接的最小链接算法,需要修改 kubeproxy 参数。
同时修改了 lb 算法后,可能还需要增加一个定时任务,检查不均衡的节点,主动断掉节点链接来促使 rebanlance 。 |
 |
3
defunct9 2023-01-18 20:47:50 +08:00 via iPhone
改成短链接
|
 |
4
zhoudaiyu OP |
 |
5
Monad 2023-01-18 21:45:04 +08:00 是否可以由 B 服务的 Pod 注册 NodeIP+NodePort 到注册中心,同时 Service 启用 externalTrafficPolicy=Local ,这样调用方 A 可以直接随机选择,他们只会给本机上的 Pod 转发。
当然这样可能要通过 affinity 保持每个 Node 只有一个对应 Pod 。 |
 |
6
ch2 2023-01-18 21:53:19 +08:00
改成基于 mq 的事件模式,不怕负载不均衡
|
|
7
zhoudaiyu OP |
 |
8
novolunt 2023-01-18 22:10:31 +08:00 via iPhone
上 istio ,svc 上 grpc 服务的问题就是通过这个解决的。不要怕没接触过,我们生产都在用
|
 |
9
jaylee4869 2023-01-18 22:10:34 +08:00
一致性哈希。选 Node IP 那边的逻辑换成顺时针方向的哈希环节点选取,这能保证 Node 级别上一定程度均衡。
Pod 层面的话,试试根据 ClientIP 做 sessionAffinity ? |
|
10
zhoudaiyu OP |
|
11
Monad 2023-01-19 00:02:38 +08:00 via iPhone
@zhoudaiyu 多个 pod 的话涉及到每个 nodeip 的权重了 如果没有这个概念调用方同等权重随机,从 pod 的角度看负载也不均衡了(除非能保证 pod 数在每个 node 一致,不过不清楚怎么办到)。
|
 |
12
rrfeng 2023-01-19 08:35:39 +08:00 via Android
这问题跟 k8s 没关系,就是长链接的负载均衡问题。
假如你有 100 个实例,只有一个客户端,怎么也不可能均匀。 |
 |
13
rushssss 2023-01-19 09:04:31 +08:00
取一个折中的办法: 在服务端或是客户端改造都行,每条长链接用过多少次之后就销毁(取值取决于你的负载情况),比如每条长链接处理过 1000 个请求就主动关闭,促使其重新建立连接,这样即能保证效率,与能保证大致的负载均衡
|
 |
14
winglight2016 2023-01-19 09:17:25 +08:00
如果 service 级的 lb 没有问题,那只需要把 pod 均匀部署到 node 上就可以了,自己设计好,通过 affinity 指定 node
长连接不推荐,全部流量都走长连接,等于瓶颈和风险都放在这个长连接上,太不靠谱了 |
 |
15
fangdaidai 2023-01-19 09:48:33 +08:00
lz 这个坑我们之前踩过,k8s 外部流量接入可以尝试下 ingress 来做负载均衡,内部转发可以用服务发现
|
 |
16
retanoj 2023-01-19 09:53:48 +08:00
有考虑过两个集群网络互通么(逃..
|
|
17
zhoudaiyu OP @fangdaidai #15 netty 需要 4 层的代理,而且 ingress 也是转到 svc 吧
|