
small-map: 一个 SIMD 加速的高效 Rust 小 HashMap 实现
ihciah · ihciah · 2023-11-02 17:21:53 +08:00 · 2333 次点击这是一个创建于 474 天前的主题,其中的信息可能已经有所发展或是发生改变。
在某些场景下,Rust 程序员会使用 smallstr 和 smallvec 来避免为小规模数据分配堆内存,其原理是尽量使数据直接放在栈上,当数据规模超过其预定大小时回落到堆实现。但是社区并没有类似的 map 实现,所以我写了一个。
如果你想对小规模数据(例如小于 16 个或者 32 个 key/value )做高效查找,又尽量不想付出分配开销时,那么欢迎你使用 small-map 这个 crate !比较推荐的场景是用来处理请求级别的 http header 、RPC header 等。
实现上,通常 hashmap 在内存中是稀疏的,但这种布局并不适用于这个目标场景:我想让其占用的栈内存尽量紧凑。一个最简单的想法是将其实现为包含 SmallVec<[(K, V); N]> 和 HashMap<K, V> 两个分支的 enum 结构,但这样用户在查找时需要付出遍历和大量 key 比较的开销。
参考 SwissTable 的设计,我将其 Group 平铺来达到紧凑的内存布局,并利用相同的 SIMD 运算来加速查找。顺序处理每个 Group 并不会有太大开销,因为 SSE2 下可以一次查找 16 个元素,而我们的使用场景就是 kv 很少的情况,所以本来就预期只有一两个 Group 。
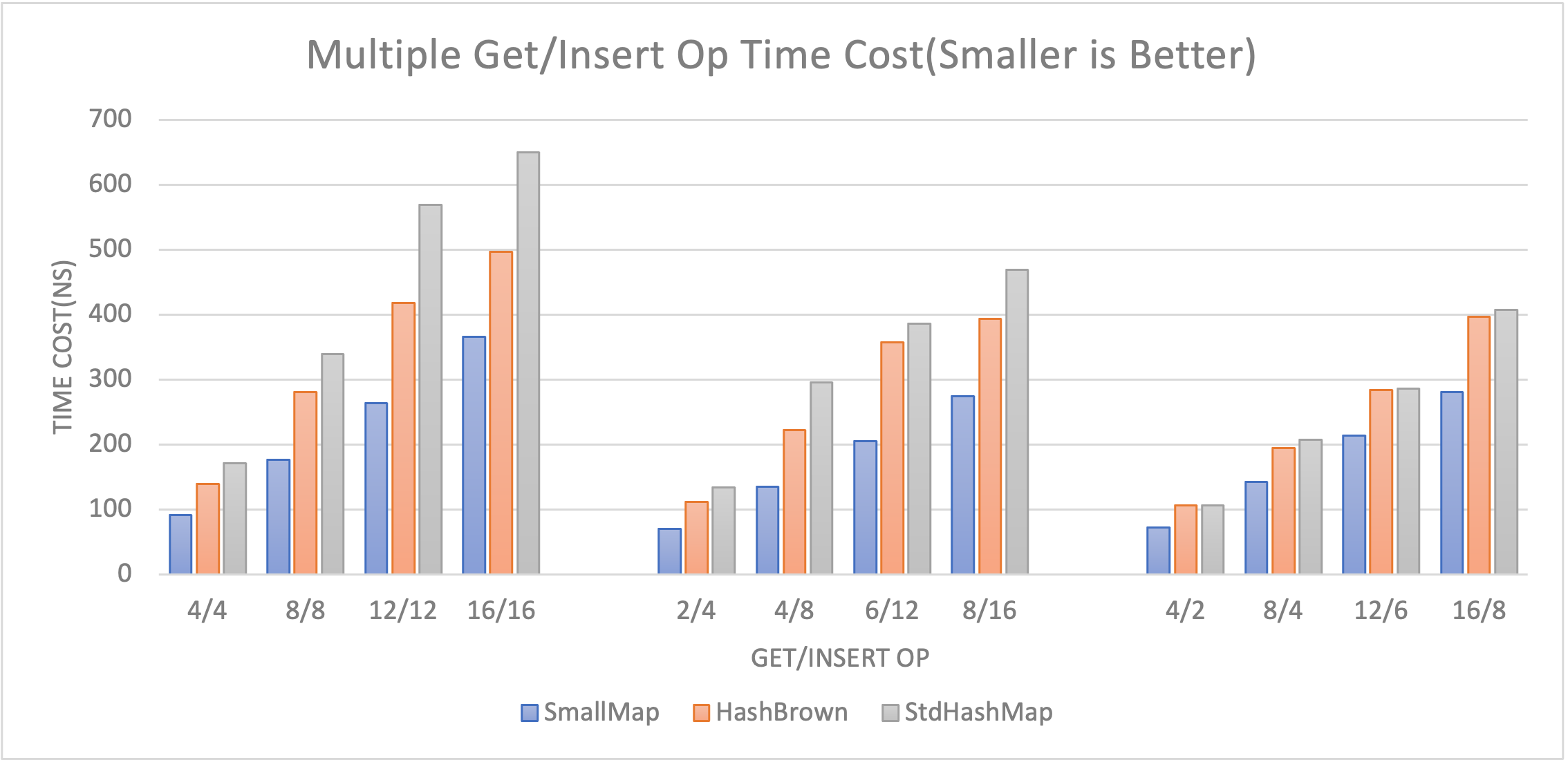 我在一个典型场景下对比了 small-map 、hashbrown 和 std hashmap ,CPU 分别有 25%~43%、25%~54% 的节省(代码仓库中有用到的 bench 代码)。
我在一个典型场景下对比了 small-map 、hashbrown 和 std hashmap ,CPU 分别有 25%~43%、25%~54% 的节省(代码仓库中有用到的 bench 代码)。
 |
1
JohnSmith 2023-11-02 17:33:01 +08:00
 牛的 牛的 |
 |
2
stephenhero 2023-11-03 11:12:58 +08:00
牛哇牛哇
|