
整点没用的:在 CD 盒子背面寻找语法树是不是搞错了什么?谈谈我第一次用 Tree-sitter 写语法解析器的感受
Contextualist · Contextualist · 270 天前 · 1829 次点击这是一个创建于 270 天前的主题,其中的信息可能已经有所发展或是发生改变。
虽然发在「分享创造」,但是这个作品大家多半用不着,本文的目的是成为大家的摸鱼读物。
起因
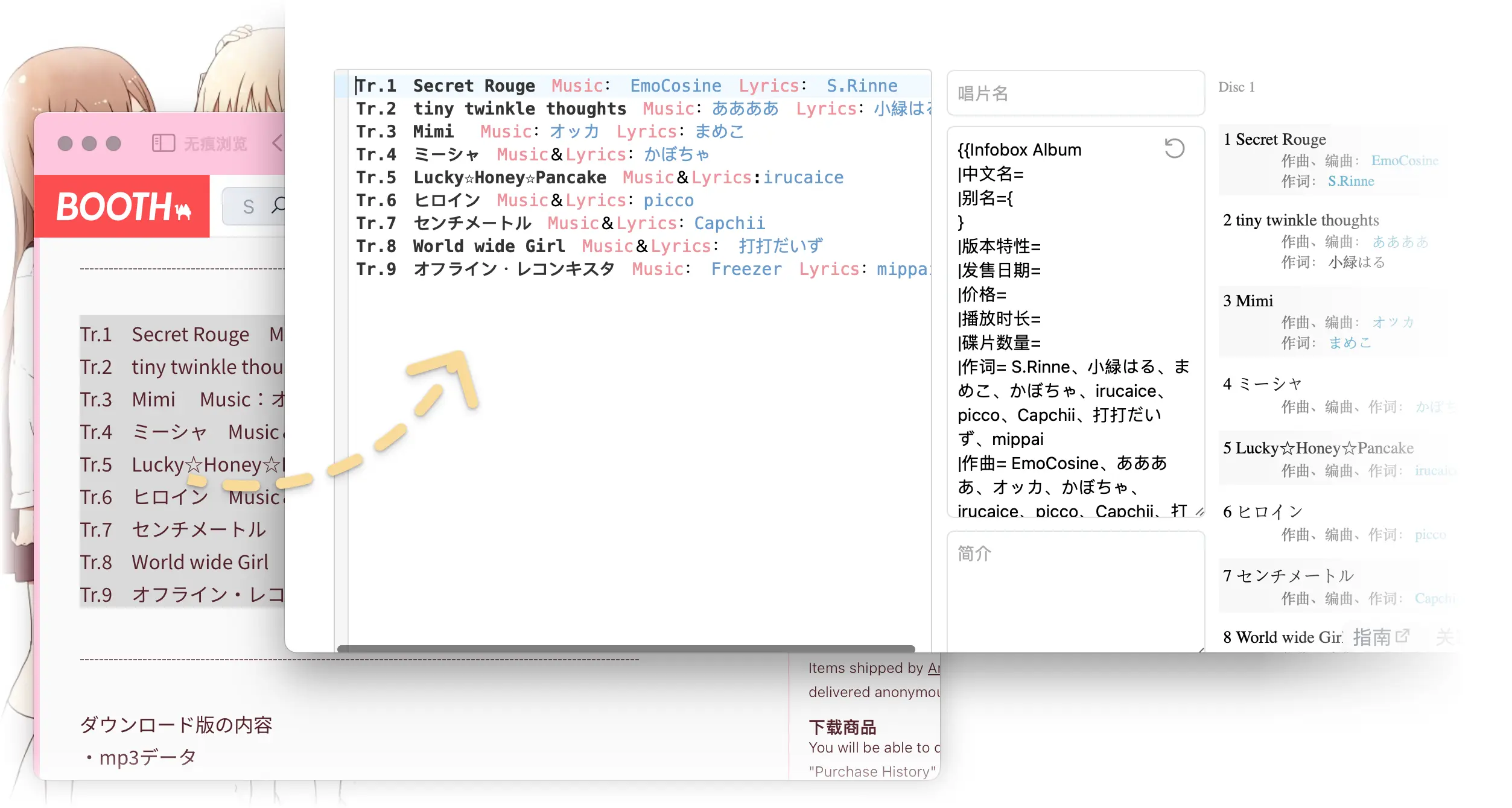
出于个人兴趣,最近在为某维基网站写用来编写条目的自动化工具。需求是把零散的唱片信息整合成维基语法。唱片信息中处理起来比较繁琐的是曲目列表,其中列出了每首曲子参与制作的分工(例如作词、作曲、编曲)。这些信息写起来没有统一标准,比如下面两个出自同一社团的不同写法的曲目列表:

在 2024 年中这个节点上,你或许会说,处理这种非结构化的数据可以上大型语言模型。但是,我想到了一门更加古老的艺术:语法解析器( syntax parser ),具体来说是上下文无关语法( CFG, context-free grammar )。
在接触了大量不同来源的唱片专辑后,我发现这些曲目信息并不是完全无结构的。虽然都是用人类自然语言写的,但因为领域约束,不同专辑的曲目信息呈现出许多趋同的特性,包括用语和排列方式。我称这样的信息为弱结构化数据( weakly structured data )……
说人话!先写上曲目名,然后写上“作曲:”,嘿,您猜怎么着,后面肯定跟者作曲家的名字呀!你这不人人都知道吗?可不是吗!
既然这些数据有一定的结构,那么我是不是可以为其定义一套语法,然后我就能拥抱现有的为 IDE 准备的全套生态了,像是毫秒级的即时语法分析检查、语法高亮、自动补全。慢着,我不就一写维基的,我要这些功能干什么?那我先讲讲最终成品是怎么样的:
所以有了语法解析器后……
从网站上把信息复制下来,基本上就可以直接解析。解析错误可以从语法高亮或者实时预览中发现,一般也不需要大改就可以成功解析。然后解析生成的维基文本就可以直接复制粘贴到维基站了。
需要快速补充信息,有自动补全
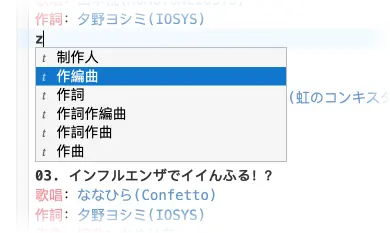
linter 可以实时提示可能缺失的信息(这个功能还没加)
原来需要逐个项目整理确认的繁琐工作就这样被转化成了轻松的交互,用程序员的工具真开心啊。
踏上 Tree-sitter 这片陌生的土地
刚开始做这个项目的时候,我也确实是抱着试一试的心态:毕竟曲目信息到头来并不是什么被严格定义的内容,它适用于上下文无关语法( CFG )那一套规则吗?最后发现,只要我的语法足够简单,CFG 总能处理个大概。题外话,其实绝大部分编程语言都不是上下文无关的,大家都是用 CFG 做初步解析,再用定制的代码解析语义相关的部分(感兴趣的可以看看这篇问答)。
我没有任何 PL 相关的背景,所以这次纯粹就是一场冒险。之前关注 Neovim 的时候听说他们把语法高亮整体迁移到了 Tree-sitter ,而 Tree-sitter 看上去是个被广泛认可的从语法生成解析器的方案。于是 我就跑去看了看他们的文档。过了惯例的安装部分,他们简单介绍了各部分的功能,然后到教程的部分……还是挺硬核的。文档经常提到如何把现有的 CFG 转译成 Tree-sitter 的定义方式,也常与 Yacc 和 Bison 等更先前的语法系统作比较。显然这个文档更倾向于对语法解析有一定背景的受众,我也没啥好抱怨的,菜,就多练。当然这也很合理,毕竟编程语言基本都有现成的严格语法定义,而很多使用 Tree-sitter 写解析器的人本身就参与制定语法。那我还是硬着头皮上了,就用试错法。使用 Tree-sitter 的开发流程还是很用户友好的:可以比较容易地添加一些测试用例做 test-driven development ;编译速度很快,也可以在命令行里试跑片段,打印出语法树和高亮:
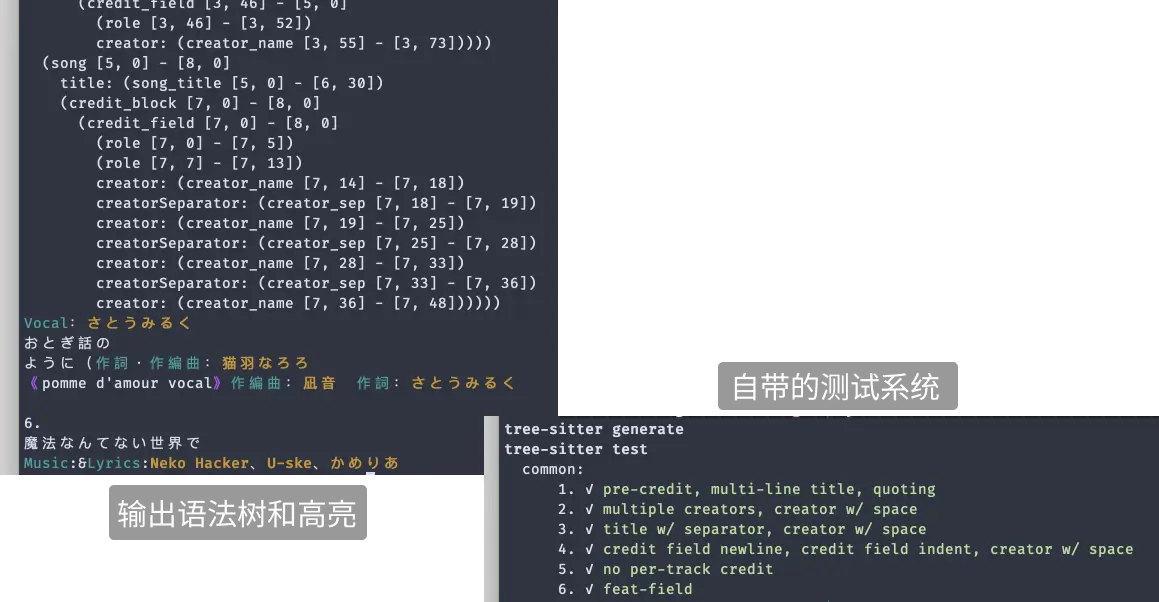
至于错误信息嘛,反正我没摸清门道,所以对于我来说就是基本上没有。解析器一般都被要求有一定程度的容错能力,对于不完全正确的输入会尽可能做部分解析,这样它才能处理写到一半的代码片段。而对于我这个正在 debug 的、不完全正确的语法,这个容错能力反而让解析错误显得晦涩难懂:被部分解析的语法树中,显示的错误很可能并不是真正引起错误的原因。所以,最后还是得凭感觉尝试。Tree-sitter 的文档说,"写语法定义需要创造力( Writing a grammar requires creativity )“,我:才疏学浅、创意枯竭。
一点现学现卖(可以跳过的技术细节)
怎么开始写 Tree-sitter 语法?网上找不到太多的教程,我在摸爬滚打也算是总结出来一两个常用的模式,还请大家斧正。
- 对正则表达式的支持很有限,基本只是个语法糖:Tree-sitter 允许用正则匹配 token ,但最终能写的可能就只有类似
[^\n]+这种。Tree-sitter 实现的是 LR parser ,可以理解为每次只往前解析一个 token ,所以正则里需要 look-ahead / look-behind 的功能(如^,$,(?:))都用不了。 - 任何规则都不可以匹配空字符串为 token:道理很简单,如果空字符串能匹配就死循环了,但是这应该是像我这样的新手会踩的第一个坑,也是一个很容易被 Tree-sitter 检测出来的问题。那么想要匹配零个或多个的情况应该写成
optional(repeat1(...))而不是repeat(...)。 -
匹配 token 数量和方式会(很玄学地)影响优先级判断:因为解析时没有上下文,自动机在每个状态下都有几种可能的状态转移方式,所以 Tree-sitter 里有一套我至今没搞明白的优先级计算方式。举两个玄学例子:
- 我试过
/.+/这个规则会太过贪心,一旦开始匹配就会一直匹配下去,而换成repeat1(/./)则可以即时让步其他规则,我猜测是因为前者被视作匹配一个 token 而后者则是多个 token 。 - 反过来的情况,一些多 token 组成的规则优先级过低,用
token(...)或token.immediate(...)可以合并为一个 token 。
- 我试过
Tree-sitter 里关于优先级和冲突解决的内容我还是云里雾里。像是各种 pred、parse precedence 和 lexical precedence 、conflicts,我并没有成功理解并使用,唯一有用的一次是乱试试出来的。
我始终没搞明白,但它就是跑得起来
就这样我一点点往上加语法,逐步可以解析出曲目名、制作人员职位、制作人员名字。解析到人名的地方时,我就停下来了。有些人名中会有空格,而有时候空格却被用作分隔人名的符号,而区分这两种情况不能单靠语法,得用后续定制的代码做语义解析了。
最终得到的语法定义的主体部分其实只有 60 行左右(代码在这里),比我用 Python 手写的 parser 原型短多了。其实完整的现代编程语言的 Tree-sitter 语法文件也大概就 1000 多行,Tree-sitter 语法的表达能力还是很强的。
语法定义确实是很简练,但是——你或许也猜到了——它很难维护:很难理解、很难增改、很难移植。
后来我想适配多一种情况,捣鼓了一会儿就接近重写了……也行,我想,那就按照我这段时间积累的经验,重写一个更好的版本。结果,写出来比之前的版本要冗长,而且之前的几个测试还过不了了。我捋清楚过后发现我好像需要 look-ahead ,所以其实我并没有捋清楚。最后扔掉了重写的版本,我发现之前的版本只需要一个“优雅”的小改动就可以了,感觉像解开了孔明锁。
后来的后来,我想把这个解析器应用到 web 端。查了一圈发现 CodeMirror 算是比较齐全的 IDE 库了,但,它只兼容作者自己开发的一个叫 Lezer 的语法。为了从 Tree-sitter 语法移植到 Lezer 语法,我用了作者提供的自动转换,然后上手修改不能转换的部分,整了好一会儿也搞不懂 Lezer 优先级,只好作罢。最后手写了个 Tree-sitter parser 到 CodeMirror 的兼容层,强行让 CodeMirror 支持了 Tree-sitter……
反正现在是磕磕绊绊地用着了,新需求也能磕磕绊绊地加。所以吧,这次大胆的尝试算是成功吧。
或许编程的目的,就是在纷乱的世界中寻找秩序吧(或者说把结构强加给非结构化的存在
第 1 条附言 · 193 天前
现在学会怎么用 lexical precedence 了。而现在语法定义的主体部分也已经差不多100行了。作为参考,也附上正文写作时的语法定义
7 条回复 • 2024-07-13 00:52:12 +08:00
 |
1
RightHand 270 天前 via Android
之前写过一个其他方面的,给你个建议,用支持 dsl 的语言写。能省不少时间。
|
 |
2
Contextualist OP @RightHand 请问是用 DSL 写哪部分?好奇你的场景和最后选择的语言?愿闻其详
Tree-sitter 语法定义文件的格式其实本身就是 DSL ,是基于 js 的。 |
 |
3
zoharSoul 270 天前
写的太棒了..
很有用又很有意思~ 感谢 |
 |
4
subframe75361 270 天前 via Android
monaco 的 textmate ?
|
|
5
Contextualist OP @zoharSoul 谢谢鼓励
只是想分享一次有趣的尝试,“有用”我就不敢当了哈哈 |
|
6
Contextualist OP @subframe75361 今天正好看到这个: https://www.v2ex.com/t/1056672#r_14983098
Tree-sitter 算是 TextMate 的继承者了 然后我记得 CodeMirror 的作者一开始写 CodeMirror 好像也是为了解决 Monaco 的一些问题 |
|
7
zoharSoul 270 天前 @Contextualist #5 因为我对 nlp 一直没什么了解, 然后在如何识别章节小说目录上一直没有特别好的办法.
>>> ``` 在 2024 年中这个节点上,你或许会说,处理这种非结构化的数据可以上大型语言模型。但是,我想到了一门更加古老的艺术:语法解析器( syntax parser ),具体来说是上下文无关语法( CFG, context-free grammar )。 在接触了大量不同来源的唱片专辑后,我发现这些曲目信息并不是完全无结构的。虽然都是用人类自然语言写的,但因为领域约束,不同专辑的曲目信息呈现出许多趋同的特性,包括用语和排列方式。我称这样的信息为弱结构化数据( weakly structured data )…… ``` 这段给了很大的启发 |