wget https://github.com/xiexiexx/PPLA/raw/main/billionsort/billionsort.cpp
clang++ -O3 billionsort.cpp
./a.out
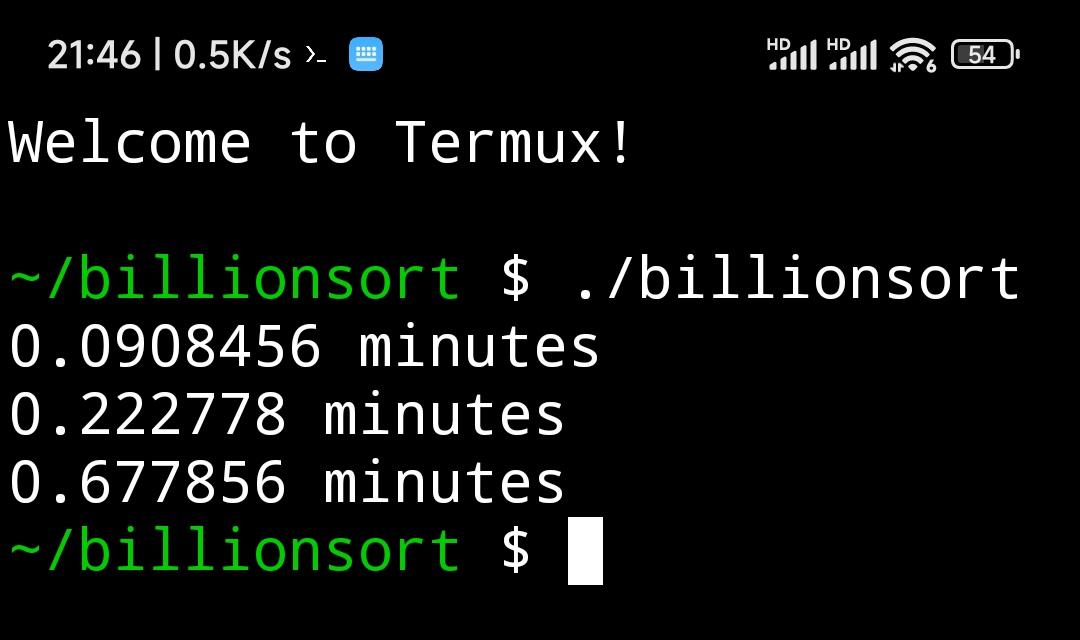
- redmi note12t 7+gen2 16+1t miui14.0.25 termux witout root
有没有 8gen3 和 9300 的老哥跑一下让我长长见识
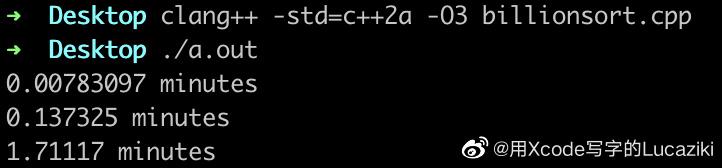
- iphone11 a13 4+128g ios17.1.1 a-shell 跑的 1 亿
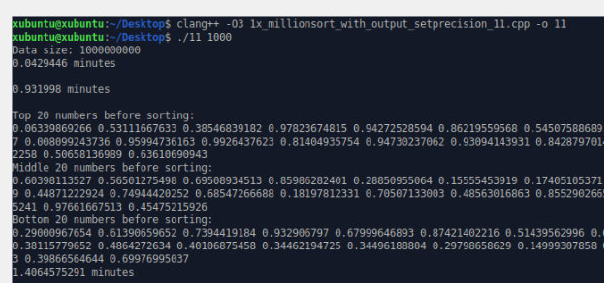
[Documents]$ ./1x_millionsort_with_output 100
Data size: 100000000
0.0027 minutes
0.02695 minutes
0.478667 minutes
- 7700k 32g xubuntu2204